來自:恆生研究院,作者: 董西孝
鏈接: http://rdc.hundsun.com/portal/article/731.html
出於對Linux操作系統的興趣,以及對底層知識的強烈慾望,因此整理了這篇文章。本文也可以作為檢驗基礎知識的指標,另外文章涵蓋了一個系統的方方面面。如果沒有完善的計算機系統知識,網絡知識和操作系統知識,文檔中的工具,是不可能完全掌握的,另外對系統性能分析和優化是一個長期的系列。
本文檔主要是結合Linux 大牛,Netflix 高級性能架構師 Brendan Gregg 更新 Linux 性能調優工具的博文,搜集Linux系統性能優化相關文章整理後的一篇綜合性文章,主要是結合博文對涉及到的原理和性能測試的工具展開說明。
背景知識:具備背景知識是分析性能問題時需要瞭解的。比如硬件 cache;再比如操作系統內核。應用程序的行為細節往往是和這些東西互相牽扯的,這些底層的東西會以意想不到的方式影響應用程序的性能,比如某些程序無法充分利用 cache,從而導致性能下降。比如不必要地調用過多的系統調用,造成頻繁的內核 / 用戶切換等。這裡只是為本文的後續內容做一些鋪墊,關於調優還有很多東西,我所不知道的比知道的要多的多,希望大家能共同學習進步。
【性能分析工具】
首先來看一張圖:

上圖是Brendan Gregg 的一次性能分析的分享,這裡面的所有工具都可以通過man來獲得它的幫助文檔,下問簡單介紹介紹一下常規的用法:
▲ vmstat--虛擬內存統計
vmstat(VirtualMeomoryStatistics,虛擬內存統計) 是Linux中監控內存的常用工具,可對操作系統的虛擬內存、進程、CPU等的整體情況進行監視。
vmstat的常規用法:vmstat interval times即每隔interval秒採樣一次,共採樣times次,如果省略times,則一直採集數據,直到用戶手動停止為止。
簡單舉個例子:

可以使用ctrl+c停止vmstat採集數據。
第一行顯示了系統自啟動以來的平均值,第二行開始顯示現在正在發生的情況,接下來的行會顯示每5秒間隔發生了什麼,每一列的含義在頭部,如下所示:
▪ procs:r這一列顯示了多少進程在等待cpu,b列顯示多少進程正在不可中斷的休眠(等待IO)。
▪
memory:swapd列顯示了多少塊被換出了磁盤(頁面交換),剩下的列顯示了多少塊是空閒的(未被使用),多少塊正在被用作緩衝區,以及多少正在被用作操作系統的緩存。
▪ swap:顯示交換活動:每秒有多少塊正在被換入(從磁盤)和換出(到磁盤)。
▪ io:顯示了多少塊從塊設備讀取(bi)和寫出(bo),通常反映了硬盤I/O。
▪ system:顯示每秒中斷(in)和上下文切換(cs)的數量。
▪ cpu:顯示所有的cpu時間花費在各類操作的百分比,包括執行用戶代碼(非內核),執行系統代碼(內核),空閒以及等待IO。
內存不足的表現:free memory急劇減少,回收buffer和cacher也無濟於事,大量使用交換分區(swpd),頁面交換(swap)頻繁,讀寫磁盤數量(io)增多,缺頁中斷(in)增多,上下文切換(cs)次數增多,等待IO的進程數(b)增多,大量CPU時間用於等待IO(wa)
▲iostat--用於報告中央處理器統計信息
iostat用於報告中央處理器(CPU)統計信息和整個系統、適配器、tty 設備、磁盤和 CD-ROM 的輸入/輸出統計信息,默認顯示了與vmstat相同的cpu使用信息,使用以下命令顯示擴展的設備統計:

第一行顯示的是自系統啟動以來的平均值,然後顯示增量的平均值,每個設備一行。
常見linux的磁盤IO指標的縮寫習慣:rq是request,r是read,w是write,qu是queue,sz是size,a是verage,tm是time,svc是service。
▲dstat--系統監控工具
dstat顯示了cpu使用情況,磁盤io情況,網絡發包情況和換頁情況,輸出是彩色的,可讀性較強,相對於vmstat和iostat的輸入更加詳細且較為直觀。在使用時,直接輸入命令即可,當然也可以使用特定參數。
如下:dstat –cdlmnpsy
▲iotop--LINUX進程實時監控工具
iotop命令是專門顯示硬盤IO的命令,界面風格類似top命令,可以顯示IO負載具體是由哪個進程產生的。是一個用來監視磁盤I/O使用狀況的top類工具,具有與top相似的UI,其中包括PID、用戶、I/O、進程等相關信息。
可以以非交互的方式使用:iotop –bod interval,查看每個進程的I/O,可以使用pidstat,pidstat –d instat。
▲pidstat--監控系統資源情況
pidstat主要用於監控全部或指定進程佔用系統資源的情況,如CPU,內存、設備IO、任務切換、線程等。
使用方法:pidstat –d interval;pidstat還可以用以統計CPU使用信息:pidstat –u interval;統計內存信息:Pidstat –r interval。
▲ top
top命令的匯總區域顯示了五個方面的系統性能信息:
1.負載:時間,登陸用戶數,系統平均負載;
2.進程:運行,睡眠,停止,殭屍;
3.cpu:用戶態,核心態,NICE,空閒,等待IO,中斷等;
4.內存:總量,已用,空閒(系統角度),緩衝,緩存;
5.交換分區:總量,已用,空閒
任務區域默認顯示:進程ID,有效用戶,進程優先級,NICE值,進程使用的虛擬內存,物理內存和共享內存,進程狀態,CPU佔用率,內存佔用率,累計CPU時間,進程命令行信息。
▲ htop
htop 是Linux系統中的一個互動的進程查看器,一個文本模式的應用程序(在控制台或者X終端中),需要ncurses。
Htop可讓用戶交互式操作,支持顏色主題,可橫向或縱向滾動瀏覽進程列表,並支持鼠標操作。
與top相比,htop有以下優點:
▲mpstat
mpstat 是Multiprocessor Statistics的縮寫,是實時系統監控工具。其報告與CPU的一些統計信息,這些信息存放在/proc/stat文件中。在多CPUs系統裡,其不但能查看所有CPU的平均狀況信息,而且能夠查看特定CPU的信息。常見用法:mpstat –P ALL interval times。
▲ netstat
Netstat用於顯示與IP、TCP、UDP和ICMP協議相關的統計數據,一般用於檢驗本機各端口的網絡連接情況。
▲常見用法:
netstat –npl 可以查看你要打開的端口是否已經打開。
netstat –rn 打印路由表信息。
netstat –in 提供系統上的接口信息,打印每個接口的MTU,輸入分組數,輸入錯誤,輸出分組數,輸出錯誤,衝突以及當前的輸出隊列的長度。
▲ ps--顯示當前進程的狀態
ps參數太多,具體使用方法可以參考man ps,常用的方法:ps aux #hsserver;ps –ef |grep #hundsun
▲
strace
跟蹤程序執行過程中產生的系統調用及接收到的信號,幫助分析程序或命令執行中遇到的異常情況。
舉例:查看mysqld在linux上加載哪種配置文件,可以通過運行下面的命令:strace –e stat64 mysqld –print –defaults > /dev/null
▲ uptime
能夠打印系統總共運行了多長時間和系統的平均負載,uptime命令最後輸出的三個數字的含義分別是1分鐘,5分鐘,15分鐘內系統的平均負荷。
▲ lsof
lsof(list open files)是一個列出當前系統打開文件的工具。通過lsof工具能夠查看這個列表對系統檢測及排錯,常見的用法:
查看文件系統阻塞 lsof /boot
查看端口號被哪個進程佔用 lsof -i : 3306
查看用戶打開哪些文件 lsof –u username
查看進程打開哪些文件 lsof –p 4838
查看遠程已打開的網絡鏈接 lsof –i @192.168.34.128
▲ perf
perf是Linux kernel自帶的系統性能優化工具。優勢在於與Linux Kernel的緊密結合,它可以最先應用到加入Kernel的new feature,用於查看熱點函數,查看cashe miss的比率,從而幫助開發者來優化程序性能。
性能調優工具如 perf,Oprofile 等的基本原理都是對被監測對像進行採樣,最簡單的情形是根據 tick 中斷進行採樣,即在 tick 中斷內觸發採樣點,在採樣點裡判斷程序當時的上下文。假如一個程序 90% 的時間都花費在函數 foo() 上,那麼 90% 的採樣點都應該落在函數 foo() 的上下文中。運氣不可捉摸,但我想只要採樣頻率足夠高,採樣時間足夠長,那麼以上推論就比較可靠。因此,通過 tick 觸發採樣,我們便可以瞭解程序中哪些地方最耗時間,從而重點分析。
想要更深的瞭解本工具可以參考:
http://blog.csdn.net/trochiluses/article/details/10261339
匯總:結合以上常用的性能測試命令並聯繫文初的性能分析工具的圖,就可以初步瞭解到性能分析過程中哪個方面的性能使用哪方面的工具(命令)。
【常用的性能測試工具】
熟練並精通了第二部分的性能分析命令工具,引入幾個性能測試的工具,介紹之前先簡單瞭解幾個性能測試工具:
更多參考: http://blog.sina.com.cn/s/blog_98822316010122ex.html。
bcc(BPF Compiler Collection): 一款使用eBPF的perf性能分析工具。一個用於創建高效的內核跟蹤和操作程序的工具包,包括幾個有用的工具和示例。利用擴展的BPF(伯克利數據包過濾器),正式稱為eBPF,一個新的功能,首先被添加到Linux 3.15。多用途需要Linux 4.1以上BCC。
更多參考:https://github.com/iovisor/bcc#tools。
最後我們再來回顧下這些性能檢測工具。
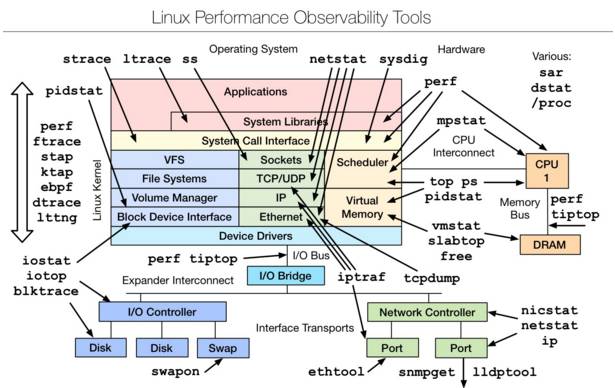
一、 Linux observability tools | Linux 性能觀測工具
二、Linux benchmarking tools | Linux 性能測評工具
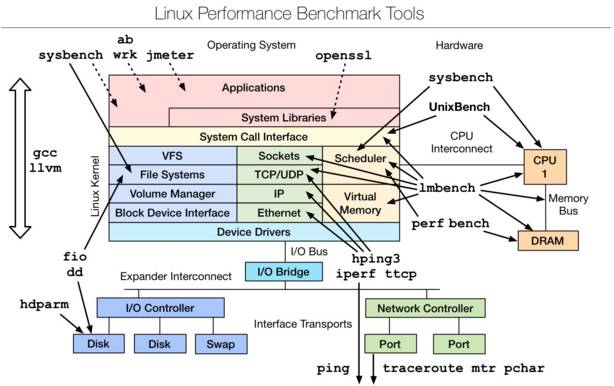
是一款性能測評工具,對於不同模塊的性能測試可以使用相應的工具,想要深入瞭解,可以參考最下文的附件文檔。
三、Linux tuning tools | Linux 性能調優工具
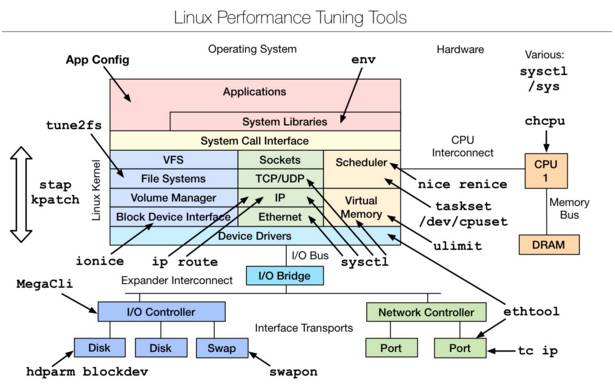
是一款性能調優工具,主要是從linux內核源碼層進行的調優,想要深入瞭解,可以參考下文附件文檔。
四、Linux observability sar | linux性能觀測工具
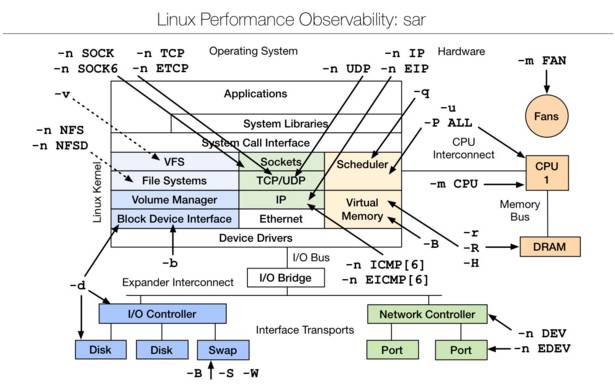
sar(System Activity Reporter系統活動情況報告)是目前LINUX上最為全面的系統性能分析工具之一,可以從多方面對系統的活動進行報告,包括:文件的讀寫情況、系統調用的使用情況、磁盤I/O、CPU效率、內存使用狀況、進程活動及IPC有關的活動等方面。
sar的常歸使用方式:sar [options] [-A] [-o file] t [n]
其中:
t為採樣間隔,n為採樣次數,默認值是1;
-o file表示將命令結果以二進制格式存放在文件中,file 是文件名。
options 為命令行選項
更多參考: http://blog.csdn.net/mig_davidli/article/details/52149993
想要更深入的瞭解,可以參考附件文件。
▲參考詳單:
LCA2017_BPF_tracing_and_more
LISA2014_LinuxPerfAnalysisNewTools
Percona2016_LinuxSystemsPerf
SCaLE_Linux_vs_Solaris_Performance2014
SCALE2015_Linux_perf_profiling
SCALE2016_Broken_Linux_Performance_Tools
SREcon_2016_perf_checklists
Velocity2015_LinuxPerfTools




