DNS BIND9 Query Statements
This chapter describes all the statements available in BIND 9.x relating to or controlling queries. Full list of named.conf statements.
additional-from-auth, additional-from-cache
additional-from-auth yes | no ;
additional-from-cache yes | no ;
additional-from-auth and additional-from-cache control the behaviour when zones have additional (out-of-zone) data or when following CNAME or DNAME records. These options are for used for configuring authoritative-only (non-caching) servers and are only effective if recursion no is specified in a global options clause or in a view clause. The default in both cases is yes. These statements may be used in a global options or in a view clause. The behaviour is defined by the table below:
| auth | cache | BIND Behaviour |
| yes | yes | BIND will follow out of zone records e.g. it will follow the MX record specifying mail.example.net for zone example.com for which it is authoritative (master or slave). Default behaviour. |
| no | no | Cache disabled. BIND will NOT follow out-of-zone records even if it is in the cache e.g. it will NOT follow the MX record specifying mail.example.net for zone example.com for which it is authoritative (master or slave). It will return REFUSED for the out-of-zone record. |
| yes | no | Cache disabled. BIND will follow out-of-zone records but since this requires the cache (which is disabled) the net result is the same - BIND will return REFUSED for the out-of-zone record. |
| no | yes | BIND will NOT follow out-of-zone records but if it is the cache it will be returned. If not in the cache BIND will return REFUSED for the out-of-zone record. |
Prior to BIND 9.5 auth-from-cache also controlled whether a recursive query (even when recursion no; was specified) would return a referral to the root servers (since these would, most likely, be available in the cache). Since BIND 9.5+ such queries are now failed with REFUSED status.
allow-query, allow-query-on
allow-query { address_match_list };
allow-query { address_match_list };
allow-query {10.0/16;};
allow-query-on {192.168.2.1;};
allow-query defines an match list of IP address(es) which are allowed to issue queries to the server. If not specified all hosts are allowed to make queries (defaults to allow-query {any;};).
allow-query-on defines the server interface(s) from which queries are accepted and can be useful where a server is multi-homed, perhaps in conjunction with a view clause. Defaults to allow-query-on {any;};) meaning that queries are accepted on any server interface.
These statements may be used in a zone, view or a global options clause.
allow-query-cache, allow-query-cache-on
allow-query-cache { address_match_list };
allow-query-cache-on { address_match_list };
allow-query-cache { 10/8; };
allow-query-cache-on { localhost; };
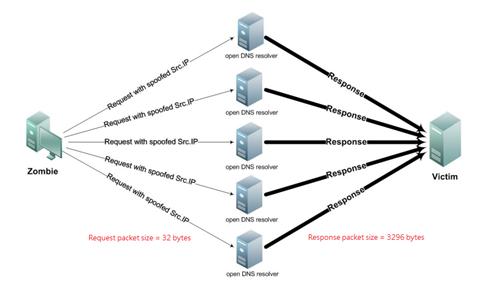
Since BIND 9.4 allow-query-cache (or its default) controls access to the cache and thus effectively determines recursive behavior. This was done to limit the number of, possibly inadvertant, OPEN DNS resolvers. allow-query-cache defines an address_match_list of IP address(es) which are allowed to issue queries that access the local cache - without access to the local cache recursive queries are effectively useless so, in effect, this statement (or its default) controls recursive behavior. Its default setting depends on:
If recursion no; present, defaults to allow-query-cache {none;};. No local cache access permitted.
If recursion yes; (default) then, if allow-recursion present, defaults to the value of allow-recursion. Local cache access permitted to the same
address_match_list as allow-recursion.
If recursion yes; (default) then, if allow-recursion is NOT present, defaults to allow-query-cache {localnets; localhost;};. Local cache access permitted to localnets and localhost only.
Both allow-query-cache and allow-recursion statements are allowed - this is a recipe for conflicts and a debuggers dream come true. Use either statement consistently - by preference allow-recursion.
allow-query-cache-on defines the server interface(s) from which queries that access the local cache are accepted and can be useful where a server is multi-homed, perhaps in conjunction with a
view clause. Defaults to allow-query-cache-on {any;};) meaning that queries that access the local cache are accepted on any server interface.
These statements may be used in a view or a global options clause.
allow-recursion, allow-recursion-on
allow-recursion { address_match_list };
allow-recursion-on { address_match_list };
allow-recursion { 10.0/16; };
allow-recursion-on { 192.168.2.3; };
Only relevant if recursion yes; is present or defaulted. allow-recursion defines a address_match_list of IP address(es) which are allowed to issue recursive queries to the server. When allow-recursion is present allow-query-cache defaults to the same values. If allow-recursion is NOT present the allow-query-cache default is assumed (localnets, localhost only). Meaning that only localhost (the server's host) and hosts connected to the local LAN (localnets) are permitted to issue recursive queries.
allow-recusion-on defines the server interface(s) from which recursive queries are accepted and can be useful where a server is multi-homed, perhaps in conjunction with a
view clause. Defaults to allow-recursion-on {any;};) meaning that recursive queries are accepted on any server interface.
These statements may be used in a view or a global options clause.
auth-nxdomain
[auth-nxdomain yes | no;]
If auth-nxdomain is 'yes' allows the server to answer authoritatively (the AA bit is set) when returning NXDOMAIN (domain does not exist) answers, if 'no' (the default) the server will not answer authoritatively. NOTE: This changes the previous BIND 8 default setting. This statement may be used in a view or a global options clause.
blackhole
blackhole { address_match_list };
blackhole defines a address_match_list of hosts that the server will NOT respond to, or answer queries for. The default is 'none' (all hosts are responded to). This statement may only be used in a global options clause.
delegation-only
delegation-only yes | no ;
delegation-only no;
delegation-only applies to hint and stub zones only and defines whether the zone will only respond with delegations (or referrals). See type for more information. The default is no. This statement may only be used in a zone clause.
deny-answer-addresses
deny-answer-addresses { address_match_list }
[ except-from { name_list } ];
deny-answer-addresses {192.168.2.0/24;}
except-from {"example.com";"example.net";};
Allows a receiving recursive name server (full function resolver) to discard a query response which contains any IP address (IPv4 or IPv6) defined in the address_match_list (while a key parameter is valid within an address_match_list it will be silently ignored in this context). The intent of the statement is to prevent DNS queries to external domains returning IP addresses that lie inside protected or private address space of the receiver (the so-called "re-binding attack").
The optional except-from ( name_list ) may contain one or more names (; separated and terminated) which will bypass the deny-answer-address processing if the query name is for a matching domain name or a subdomain of a domain name that appears in the name_list. In the above example if a query from any domain responds with any address in the network block 192.168.2.0 to 192.169.2.255 it will be discarded (and a SERVFAIL message returned to the client which issued the original query) unless it is returned from a query to the domain or any subdomain of either example.com or example.net (both are defined in the except-from parameter which bypasses the filtering check). Thus, if a query to the name servers of domain example.com is issued for www.example.com and it returns an A record of 192.168.2.45 it will be accepted (it was defined in the except-from name_list) whereas if a query was issued to, say, the name servers for the domain someexternaldomain.com and it returns an A record of 192.168.2.45 it will be discarded. The statement may appear in a global
options clause.
deny-answer-aliases
deny-answer-aliases { name_list }
[ except-from { name_list } ] ;
deny-answer-aliases {"example.com";"example.net";}
except-from {"example.com";"example.net";};
deny-answer-aliases is similar to deny-answer-addresses but operates on any CNAME (or DNAME) records returned. The except-from ( name_list ) parameter allows the user to optionally select names which can bypass the filter processing. In the above example if a query returns a CNAME pointing to the domain name (or any subdomain) of either example.com or example.net then the response will be discarded (and a SERVFAIL message returned to the client which issued the original query) unless it is returned from a query to the domain (or any subdomain) of either example.com or example.net (both are defined in the except-from parameter which bypasses the filtering check). Thus, if a query to the name servers of the domain example.com is issued for www.example.com and it returns a CNAME pointing to, say, fred.example.com it will be accepted (it was defined in the except-from name_list) whereas if a query was issued to, say, the name servers of the domain someexternaldomain.com and it returns a CNAME pointing to, say, fred.example.com it will be discarded. The statement may appear in a global
options clause.
disable-empty-zone
disable-empty-zone zone_name ;
disable-empty-zone "168.192.IN-ADDR.ARPA";
By default
empty-zones-enable is set to yes which means that reverse queries for IPv4 and IPv6 addresses covered by RFCs 1918, 4193, 5737 and 6598 (as well as IPv6 local address (locally assigned), IPv6 link local addresses, the IPv6 loopback address and the IPv6 unknown address) but which is not covered by a locally defined zone clause will automatically return an NXDOMAIN response from the local name server. This prevents reverse map queries to such addresses escaping to the DNS hierarchy where they are simply noise and increase the already high level of query pollution caused by mis-configuration. disable-empty-zone may be used to selectively turn off empty zone responses for any particular zone in which case the query will escape to the DNS hierarchy. To turn off more than one empty-zone, multiple disable-empty-zone statements must be defined. There is no need to turn off empty-zones for which the user has defined a local
zone clause since BIND automatically detects this, similarly if the name server forwards all queries, the empty-zone process is automatically inhibited. Other than name servers which delegate to the IN-ADDR.ARPA or IP6.ARPA domains, it is not clear who would want to use this statement. Perhaps more imaginative readers can see uses. The statement may appear in a global options clause or a view clause.
Note: An empty zone contains only an SOA and a single NS RR.
empty-contact name ;
empty-contact "hostmaster.example.com";
By default empty-zones-enable is set to yes which means that reverse queries for IPv4 and IPv6 addresses covered by RFCs 1918, 4193, 5737 and 6598 (as well as IPv6 local address (locally assigned), IPv6 link local addresses, the IPv6 loopback address and the IPv6 unknown address) but which is not covered by a locally defined zone clause will automatically return an NXDOMAIN response from the local name server. This prevents reverse map queries to such addresses escaping to the DNS hierarchy where they are simply noise and increase the already high level of query pollution caused by mis-configuration. The NXDOMAIN response provides the SOA RR in the Authority Section:. The
SOA RR contains a number of fields which are synthesized by the empty zone feature. One of the fields is the mail address of a zone contact (the RNAME field). By default this is set to the value "." (a null value). empty-contact may be used to define an alternative email address which will be used in the SOA RR for all empty-zone responses. The example above defines hostmaster@example.com as an email address to which questions regarding this zone may be sent. The statement may appear in a global options clause or a view clause.
Note: An empty zone contains only an SOA and a single NS RR.
empty-server
empty-server name ;
empty-server "ns1.example.com";
By default empty-zones-enable is set to yes which means that reverse queries for IPv4 and IPv6 addresses covered by RFCs 1918, 4193, 5737 and 6598 (as well as IPv6 local address (locally assigned), IPv6 link local addresses, the IPv6 loopback address and the IPv6 unknown address) but which is not not covered by a locally defined zone clause will automatically return an NXDOMAIN response from the local name server. This prevents reverse map queries to such addresses escaping to the DNS hierarchy where they are simply noise and increase the already high level of query pollution caused by mis-configuration. The NXDOMAIN response provides the SOA RR in the Authority Section:. The
SOA RR contains a number of fields which are synthesized by the empty zone feature. One of the fields is the name of one of the zones names servers (the MNAME field). By default this is set to the value of the synthesized domain name. empty-server may be used to define an alternative name which will be used for all empty-zone responses. The example above indicates that ns1.example.com will appear as the name server name (MNAME) is all SOA RRs for empty-zone responses. The statement may appear in a global options clause or a view clause.
Note: An empty zone contains only an SOA and a single NS RR.
empty-zones-enable
empty-zones-enable yes | no ;
empty-zones-enable no;
By default empty-zones-enable is set to yes which means that reverse queries for IPv4 and IPv6 addresses covered by RFCs 1918, 4193, 5737 and 6598 (as well as IPv6 local address (locally assigned), IPv6 link local addresses, the IPv6 loopback address and the IPv6 unknown address) but which is not not covered by a locally defined zone clause will automatically return an NXDOMAIN response from the local name server. This prevents reverse map queries to such addresses escaping to the DNS hierarchy where they are simply noise and increase the already high level of query pollution caused by mis-configuration. The empty-zone feature may be turned off entirely by specifying empty-zones-enable no; or selectively by using one or more disable-empty-zone statements. The statement may appear in a global options clause or a
view clause.
Note: An empty zone contains only an SOA and a single NS RR.
forward
forward ( only | first );
forward is only relevant in conjunction with a valid forwarders statement. If set to 'only' the server will only forward queries, if set to 'first' (default) it will send the queries to the forwarder and if not answered will attempt to answer the query. This statement may be used in a zone, view or a global options clause.
forwarders
forwarders { ip_addr [port ip_port] ; [ ip_addr [port ip_port] ; ... ] };
forwarders { 10.2.3.4; 192.168.2.5; };
forwarders defines a list of IP address(es) (and optional port numbers) to which queries will be forwarded. Only relevant when used with the related forward statement. This statement may be used in a zone, view or a global options clause.
minimal-responses
minimal-responses yes | no ;
minimal-responses yes ;
If yes the server will only add records to the authority and additional data sections when they are required by the protocol, for instance, delegations and negative responses. This may improve the performance of the server by reducing outgoing data volumes. The BIND default is no. This statement may be used in a view or a global options clause.
prefetch
prefetch expiry-ttl-seconds [threshold-ttl-secs];
prefetch 5 ;
Introduced with BIND 9.10. This statement applies to recursive servers (full service resolvers) and allows the user to control the time at which the cache may be refreshed. If the recursive server waits until the TTL of any cached record has reached zero then there will be a visible delay while the replacement record is being fetched from the authoritative server. In order to increase user visible performance BIND (since 9.10) by default now prefetches records if it accesses a cached record which has 2 seconds or less of TTL remaining. The prefetch statement allows the user to control this behaviour by defining the expiry-ttl-seconds which may lie in the range 0 to 10 seconds. The value 0 indicates that prefetch should be disabled (the cache will only be updated when the TTL reaches 0), values in the range 1 to 10 indicate that if a cached record is accessed and its remaining TTL is equal to or less than expiry-ttl-seconds the record will be prefetched to ensure consistent user performance (values greater than 10 will be silently reduced to 10).
The optional threshold-ttl-seconds defines the minimum number of seconds of the TTL on the original record to invoke prefetching. If not defined the default for this value is 9 seconds. Thus, if a record is read into the cache with an original TTL of 5 seconds then, assuming the default threshold-ttl-seconds, prefetching is inhibited for that record (it is less than the 9 second default value). The threshold-ttl-seconds must be at least 6 seconds greater that the expiry-ttl-seconds. If this is not the case BIND will silently increase threshold-ttl-seconds.
While on its face this looks as if records can never be discarded from the cache, this is not the case. The prefetch algorithm will in practise only be invoked for high activity cached records since these will, by their nature, be frequently accessed and thus will trigger prefetch behavior checks and action. Low activity records are, by their nature, accessed infrequently and therefore will most likely not invoke prefetch behavior checks and action - they will naturally reach zero and be discarded from the cache. This statement may be used in a global options clause.
query-source[-v6]
query-source [ address ( ip_addr | * ) ] [ port ( ip_port | * ) ];
query-source address 192.168.2.3 ;
query-source-v6 [ address ( ip_addr | * ) ] [ port ( ip_port | * ) ];
query-source-v6 address * port 1188;
Defines the IP address (IPv4 or IPv6) and optional port to be used as the source for outgoing queries from the server. The BIND default is any server interface IP address and a random unprivileged port (1024 to 65535). The optional port is only used to control UDP operations. avoid-v4-udp-ports and avoid-v6-udp-ports can be used to prevent selection of certain ports. This statement may be used in a view or a global options clause.
Health Warning: Use of this option to define a fixed port number is extremely dangerous and can quickly lead to cache poisoning when used with any caching DNS server definition. An attacker normally has to guess both the transaction ID and the port number (both 16 bit values). If the port is fixed the bad guys have only to guess the transaction ID. You just made their job a lot easier. Don't do it.
recursion
recursion yes | no;
If recursion is set to 'yes' (the default) the server will always provide recursive query behaviour if requested by the client (resolver). If set to 'no' the server will only provide iterative query behaviour - normally resulting in a referral. If the answer to the query already exists in the cache it will be returned irrespective of the value of this statement. This statement essentially controls caching behaviour in the server. The allow-recursion statement and the view clauses can provide fine-grained control. This statement may be used in a view or a global options clause.
recursive-clients
recursive-clients number;
recursive-clients 25;
Defines the number of simultaneous recursive lookups the server will perform on behalf of its clients. BIND 9 default is 1000, that is, it will support 1000 simultaneous recursive lookup requests - which should be enough! This statement may only be used in a global options clause.
resolver-query-timeout
resolver-query-timeout seconds;
resolver-query-timeout 5;
Applies only to recursive name servers (full service resolvers) and defines the maximum time in seconds a recursive name server will take to perform a recursive operation before returning an error to the requesting client. May take any value between 10 (the default) and 30, with the special value 0 interpreted as the default (10 seconds - go figure). This statement may only be used in a global options clause.
response-policy
The response-policy statements allows BIND to intercept all queries and, based on a number of triggers and actions, to modify the returned responses. The feature is complex and is described on a Response Policy Zone page. It can only appear once in a global options clause.
root-delegation-only
root-delegation-only [ exclude { "domain_name"; ... } ];
root-delegation-only exclude { "com"; "net" };
If present indicates that all responses will be referrals or delegations. The optional exclude list consist of one or more domain_name (a quoted string) parameters. This statement is intended to be used for root domains (the gTLDs and ccTLDs) but the delegation-only statement may be to create the same effect for specific zones. This statement may be used in a view or a global options clause.
rrset-order
rrset-order { order_spec ; [ order_spec ; ... ]
rrset-order defines the order in which multiple records of the same type are returned. This works for any record type in which the records are similar not just A or AAAA RRs and covers results in the ANSWER SECTION and the ADDITIONAL SECTION. The default is cyclic (round-robin).
The full specification of rrset-order is shown below. An 'order_spec' is defined as:
class class_name ][ type type_name ][ name "domain_name"] order ordering;
Where 'class_name' is the record class, for example, IN (default is 'any'), type is the Resource Record type (if none specified defaults to 'any'), domain_name limits the statement to a specific domain suffix and defaults to root (all domains), order is a key word and ordering may take one of the following values:
- fixed - records are returned in the order they are defined in the zone file
- random - records are returned in a random order
- cyclic - records are returned in a round-robin fashion
Note: For reasons best known to the ISC (BIND's author) the fixed value is now (BIND 9.6+) only available if the configure option --with-fixed-rrset is used in the build. Neither BSD nor Debian standard packages use this option. This is likely to be true for Fedora and other RPMs but has not been verified (use named -V to check). For practical purposes only cyclic and random are the available choices.
Examples
Defines that all equal records for all domains will be returned in random order.
rrset-order {order random;};
Defines that all equal MX records for example.com will be returned in random order all others in cyclic order.
rrset-order {type MX name "example.com" order random; order cyclic};
This statement may be used in a view or a global options clause. (For more information on DNS based resilience and load balancing techniques see this article.)
sortlist
sortlist { address_match_list; ... };
sortlist { {10.2/16; };};
The sortlist statement is used to order RRsets (groups of equal RRs) for use by a resolver (a client). It is the client side of the rrset-order statement and can work against the rrset-order statement when being used as part of a load-balancing configuration in that rrset-order may carefully deliver equal RRs in its order of preference to a remote resolver that may then proceed to re-order them with a sortlist statement! The sortlist statement attempts to order returned records based on the IP address of the client that initiated the request. This statement may only be used in a global options or a view clause.
(For more information on DNS based resilience and load balancing techniques see this article.)
The address_match_list is used very differently from its use in all other statements and assumes that each element of the address_match_list is itself an address_match_list, it becomes a nested address_match_list and is enclosed in braces (curly brackets). Processing depends on whether there is one or more than one element in the nested address_match_list. In the simple case of one element as in the above example if the client's IP address matches 10.2/16 i.e. lies in range 10.2.0.0 to 10.2.255.255) and there are any IP addresses in the response in the same range they will be the first records supplied in the response. Any remaining records will be sorted according to the rrset-order (default is cyclic). If no match is found the records are returned in the order defined by the rrset-order or its default value (cyclic). If two elements are provided in the address match list then the second element is assumed to be an ordered list of preferences. This is best illustrated by an example. Assume the zone example.com has a zone file with multiple A RRs for lots.example.com:
// zone file example.com
$ORIGIN example.com.
lots IN A 192.168.3.6
IN A 192.168.4.5
IN A 192.168.5.5
IN A 10.2.4.5
IN A 172.17.4.5
The client side server has a sortlist statement as shown below:
options {
....
sortlist {
{// 1st preference block start
192.168.4/24; // 1st client IP selection matches any of these
{10.2/16; // return any of these response IPs as 1st preference
172.17.4/24; // 2nd preference
};
}; // end first block
{ // second preference block
192.168.5/24; // 2nd client IP selection matches any of these
{192.168.4/24; // return any of these response IPs as 1st preference
172.18.4/24; // 2nd preference
10.2/16; // 3rd preference
};
}; // end second block
}; // end sortlist
};
If the client, say a resolver, with an IP address of 192.168.5.33 issues an A query for lots.example.com then the RRs will be returned in the following order:
192.168.4.5
10.2.4.5
192.168.3.6
192.168.5.5
172.17.4.5
The results are computed as follows. The top level of the address_match_list is searched against the client IP (192.168.5.33) address and matches the line with a comment beginning "2nd client IP selection", the nested address_match_list is then treated as an ordered list for the A query result IPs (not the client IPs). The line with a comment terminating with "1st preference" matches so 192.168.4.5 becomes first in returned list, the line with the comment "2nd preference" does not match the returned IPs, the line with the comment "3rd preference" matches so 10.2.4.5 becomes second in the returned list and the remaining 3 RRs do not match any item in the address_match_list so are returned according to the rrset-order statement or its default (cyclic) if not defined.
原文出處:DNS BIND9 Query Statements