



 圖片來源: https://pixabay.com/photos/tree-landscape-field-branch-696839/
圖片來源: https://pixabay.com/photos/tree-landscape-field-branch-696839/
架構面試題,這系列好久沒寫了。這次來探討一下,怎麼妥善的用 RDBMS 來處理樹狀結構的做法吧。
即使 NOSQL 風行了這麼多年,現在還是有不少服務背後是用 RDBMS 在處理資料的。RDBMS + SQL 是個絕配,將資料轉成表格,加上結構化的查詢就能解決過去 80% 的問題了。不過 Tree 這種資料結構,在 RDBMS 裡面就是格格不入。幾種 Tree 的基本操作,在 RDBMS 裡面都要花些心思轉換才能夠妥善處理。例如不限定階層的儲存、查詢某個節點以下 (不限定階層) 的所有子節點,或是 Tree 的搬移、刪除等等操作都是。如果用 RDBMS 的關聯性來處理 Tree Node 跟 Node 之間的關聯,就會衍生幾個階層就需要 Join 幾次的困境 (我不可能無限制的一直 Join 下去啊)。如果搭配特殊語法 (如 T-SQL CTE), 或是用 programming language 搭配或許能夠解決, 不過你就必須在複雜度與效能間做取捨了。
我覺得這是個不錯的題目,能鑑別出你的基礎知識夠不夠札實,能否靈活運用;也能看出你是否容易被既有的工具或是框架限制住做法的測驗。這邊先不討論 tree 到底該不該擺在 RDBMS 上面處理這種議題,那是另一個層次的討論。如果背後的 storage 就限定在 RDBMS 的話,我想探討的是我們有哪些方法能夠妥善的處理他?
開始前的準備
我先把需求收斂定義一下好了。樹狀資料的應用很多,我就先以最常見的 file system 為例。 File system 有目錄 (folder) 跟檔案 (file) 兩種主要的 node, folder 是個容器,底下可以包含其他的 folder 或是 file. 在不考慮 shortcut 或是 symbol link 這類機制的話,一個 folder 或是 file 不能同時放在一個以上的 folder 內。簡單的說就是個標準的 tree 結構。
我期望在這樣的結構下,要有效率的完成這幾種 operation:
- 搜尋某個目錄下 (包含所有子目錄) 符合的檔案清單
- 目錄搬移 (move) 的操作
- 目錄刪除 (delete) 的操作
為了準備測試資料,我特地寫了個 小程式,把我目前電腦的 C:\ 下所有的目錄與檔案爬出來,存到 SQL database 內當作範例。基本上我的電腦大概就是裝好 windows 10 + visual studio 而已,沒有太多有的沒的東西 (我沒勇氣爬 D:\ 給大家看 XDD)。以我寫這篇文章當下的狀態,我的 C:\ 的狀況如下:
- Total Dir(s): 218817
- Total File(s): 1143165
- Total File Size: 231712 MB
- Max Dir Level: 18
- Max Files In One Dir: 83947
- Total Scan Time: 1199.42 sec. (FPS: 953.10 files/sec)
接下來,後面的例子都會用同一份資料為準來進行這幾項測試,並且用 SQL 的執行計劃來評估 cost:
- 模擬
dir c:\windows的結果,列出c:\windows下的目錄與檔案清單,統計檔案的大小 - 模擬
dir /s /b c:\windows\system32\*.ini, 找出所有位於c:\windows\system32目錄下 (包含子目錄) 所有副檔名為.ini的檔案清單 - 模擬
mkdir c:\windows\backup - 模擬
move c:\users c:\windows\backup - 模擬
rm /s /q c:\windows\backup(叔叔有練過,好孩子不要學)
方案 1, 紀錄上一層目錄ID
最直覺的方式,就是這個做法了。基本的結構就是一個目錄一筆資料,存放自己的 ID 以及上一層 ID。因為這種結構,上層 ID 也是參考到同一個 table 的另一筆資料的 ID,需要關聯查詢時就必須自己跟自己 join, 因此也叫做 self join。
先舉個簡單的例子來說明:
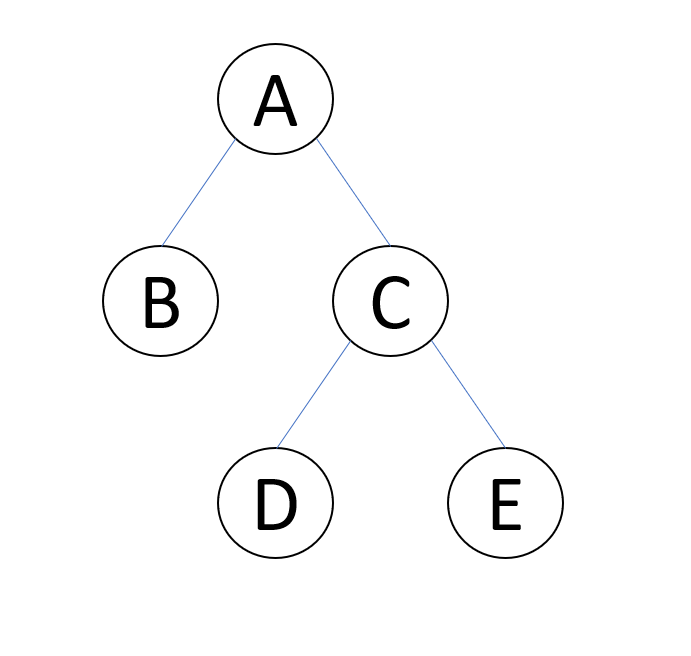
那麼資料表應該長這樣:
| ID | PARENT_ID |
|---|---|
| A | NULL |
| B | A |
| C | A |
| D | C |
| E | C |
用這概念,直接拉出 SQL table schema:
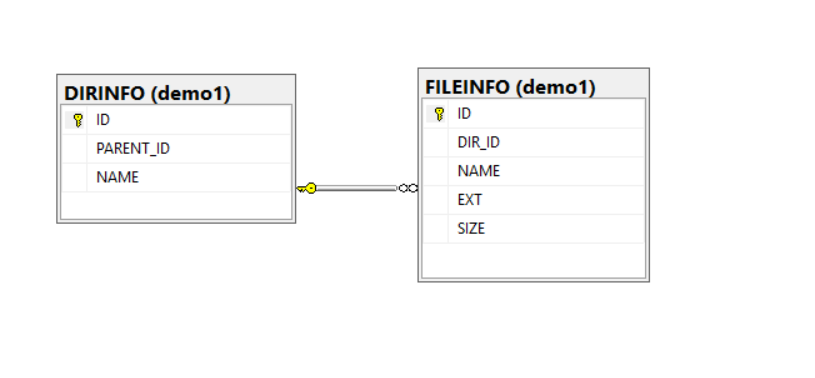
很直覺的結構,設計 schema 本身是小事,直接來看看這五項需求該如何面對…
需求 1, 查詢指定目錄下的內容
模擬
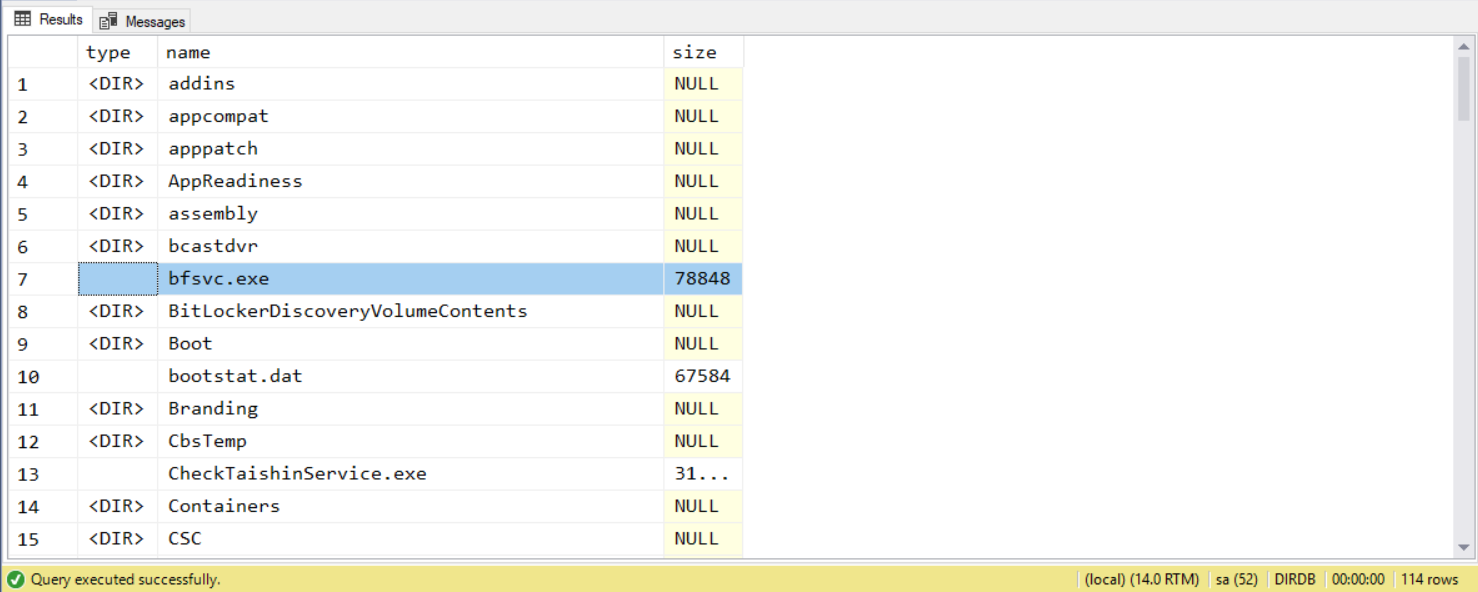
dir c:\windows的結果,列出c:\windows下的目錄與檔案清單,統計檔案的大小
直接來看一下,這結構該怎麼處理這兩個查詢需求。要列出檔案與清單,其實是小菜一碟。先找出 c:\windows 的目錄 ID:
;
ID
PARENT_ID
'
print @root
知道 c:\windows 的目錄 ID 之後,剩下的需求就很無腦了,不做解釋直接看結果:
;
ID
PARENT_ID
'
-- list DIR
select NAME from demo1.DIRINFO where PARENT_ID = @root
-- list FILE
select NAME, SIZE from demo1.FILEINFO where DIR_ID = @root
查詢結果:
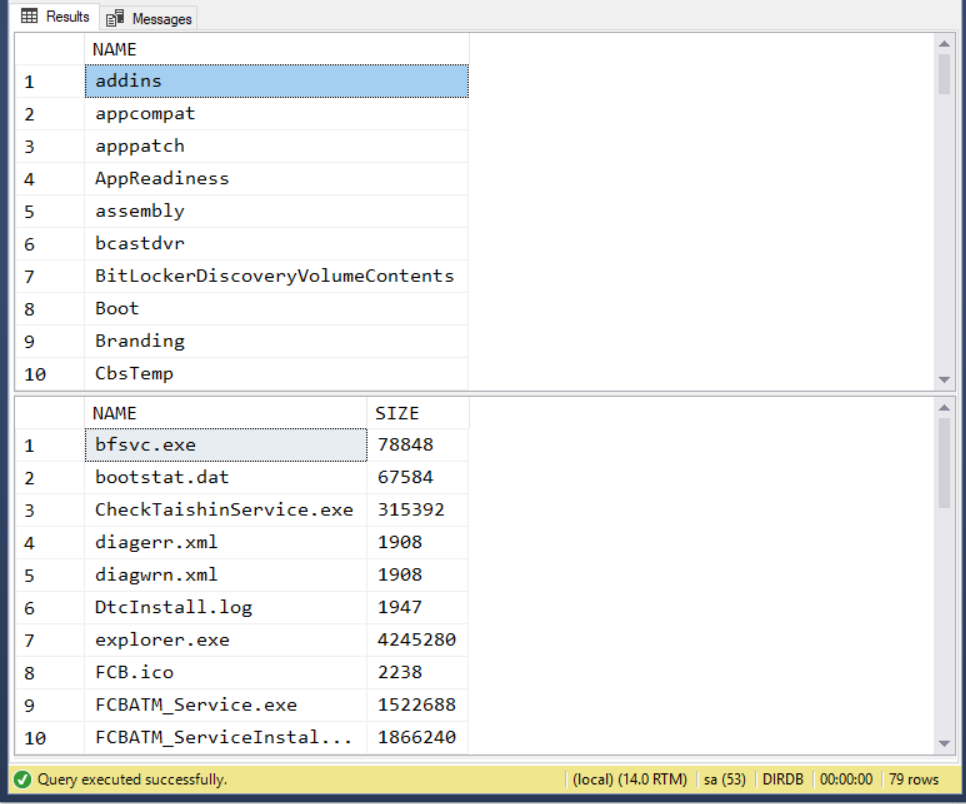
要模擬就模擬到位一點,格式調整一下:
;
ID
PARENT_ID
'
select * from
(
select '' as type, name, NULL as size from demo1.DIRINFO where PARENT_ID = @root
uni-on
select as type, NAME as name, SIZE as size from demo1.FILEINFO where DIR_ID = @root
) IX order by name asc
查詢結果:
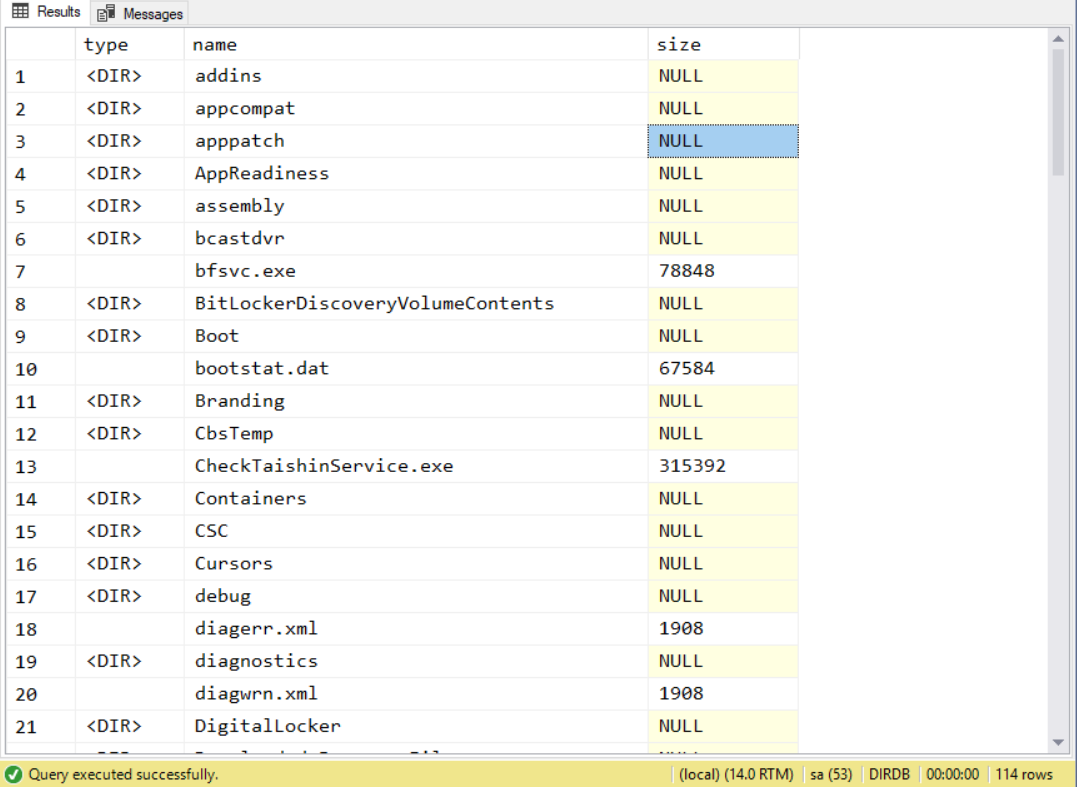
執行時間: 00:00:00.279 (sec) 執行計畫 (Estimated Subtree Cost): 0.516889
跟我自己的電腦執行 dir c:\windows 的結果對照一下:
C:\Windows>dir /a
Volume in drive C is OS
Volume Serial Number is 1C40-8489
Directory of C:\Windows
2019/05/11 上午 10:20 .
2019/05/11 上午 10:20 ..
2018/09/15 下午 03:33 addins
2018/12/02 上午 08:42 appcompat
2019/05/23 下午 10:14 apppatch
2019/05/27 上午 08:03 AppReadiness
2019/05/27 上午 08:08 assembly
2019/05/23 下午 10:14 bcastdvr
2018/09/15 下午 03:28 78,848 bfsvc.exe
2018/09/15 下午 05:08 BitLockerDiscoveryVolumeContents
2018/09/15 下午 03:33 Boot
2019/05/27 下午 08:12 67,584 bootstat.dat
2018/09/15 下午 03:33 Branding
(中間內容省略)
2018/09/15 下午 03:29 11,776 winhlp32.exe
2019/05/25 下午 07:11 WinSxS
2018/09/15 下午 05:08 316,640 WMSysPr9.prx
2018/09/15 下午 03:29 11,264 write.exe
2018/12/01 下午 12:12 zh-TW
35 File(s) 16,313,953 bytes
81 Dir(s) 233,929,641,984 bytes free
C:\Windows>
這查詢沒甚麼困難,扣掉檔案系統內建的 . 跟 .. 兩個目錄, SQL 查詢的總數跟 DIR 列出來的數字是一致的,第一題算是輕鬆過關。
需求 2, 查詢指定目錄下的內容 (遞迴)
模擬
dir /s /b c:\windows\system32\*.ini, 找出所有位於c:\windows\system32目錄下 (包含子目錄) 所有副檔名為.ini的檔案清單
這個開始棘手一點了。麻煩的部分是,每要往下找一層,就得將 DIRINFO 自己跟自己 self join 一次,就可以往下找一層。但是我不知道有幾層啊? 因此要嘛搭配 code 用遞迴 (recursive) 的方式一路查下去,或是 SQL 必須在有限的階層下通通找一次,不過這兩個方法都不大好看,重點是難以直接在 SQL 內處理完畢。
階層的問題,在這案例裡面會碰到兩次,一個是先找出 c:\windows\system32 的 ID, 這邊按照順序是 c:\ 底下的 windows 底下的 system32, 由於階層明確,我還可以笨一點,直接 self join 三層就可以找到:
;
ID
from
join
join
PARENT_ID
'
select @root
我刻意先示範蠢一點的作法,這方法笨,可是可以找的到答案。但是我不曉得 c:\windows\system32 目錄以下到底還有幾層,總不可能這樣無腦的一直寫下去吧! Microsoft 替這種問題,在 SQL 2005 以後就添加了 CTE (Common Table Expression) 的語法,嘗試解決這問題。
直接來看這個範例,我先列出 c:\windows\system32 下的所有子目錄,搜尋的過程中同時組合出正確的相對路徑:
-- 我直接填上上一個範例查到的 ID
;
as
(
)
DIRINFO
root
all
)
ID
)
DIR_CTE
這段 SQL 的執行結果:
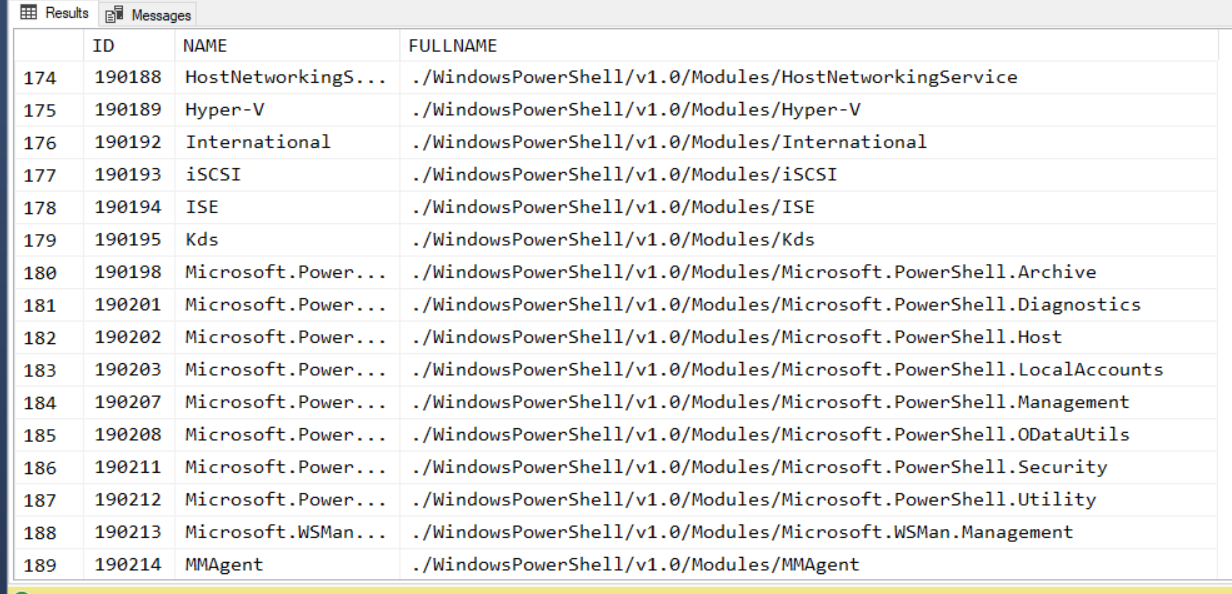
這邊簡單說明一下 CTE 的觀念,語法與範例等等有興趣的可以自行參考 Microsoft 官方文件:
簡單的說,CTE 就像是很靈活的 VIEW 一樣,就是用一段 SQL Query 定義的 VIEW,讓後續的 SQL Script 可以操作他。特別的是 CTE 的定義可以自己參考自己,就類似 programming language 自己呼叫自己的遞迴運作模式一般。用這個特性,像這類樹狀結構的處理就會變得非常容易。
不過語法好寫,不等於效能會跟語法一樣簡潔快速。CTE 寫的不好的話,是會引發災難的。CTE 只是讓你能寫出簡單易懂的 recursive 查詢。執行效能大致上跟前面自己 self join 是同一個層級,不會因為語法簡潔就讓你的查詢突然變得飛快。寫的時候請特別留意會不會不小心就跑過頭了。你可以用 MAXRECURSION 來限制遞迴的呼叫層數,避免寫的很糟糕的 CTE 陷入無窮迴圈。
回到我們要解決的問題,既然目錄結構都查出來了,要查出檔案就不是太大問題了。只需要再多 join 一次 demo1.FILEINFO,就可以取得檔案清單。這次我貼上一段完整的 T-SQL:
;
-- step 1, 找出 c:\windows\system32 的 ID
ID
from
join
join
PARENT_ID
'
-- step 2, 建立 c:ystem32 下的所有 DIR LIST 清單 (CTE)
;with DIR_CTE(ID, NAME, FULLNAME) as
(
select ID, NAME, cast('' + NAME as ntext)
from demo1.DIRINFO
where PARENT_ID = @root
uni-on all
select D1.ID, D1.NAME, cast(concat(D2.FULLNAME, '', D1.NAME) as ntext)
from demo1.DIRINFO D1 inner join DIR_CTE D2 on D1.PARENT_ID = D2.ID
)
-- step 3, 依據 (2), 找出所有 (2) 目錄下, 附檔名為 .ini 的檔案及大小清單
select concat(D.FULLNAME, '', F.NAME) as NAME, F.SIZE
from DIR_CTE D inner join demo1.FILEINFO F on D.ID = F.DIR_ID
where F.EXT = ''
查詢結果:
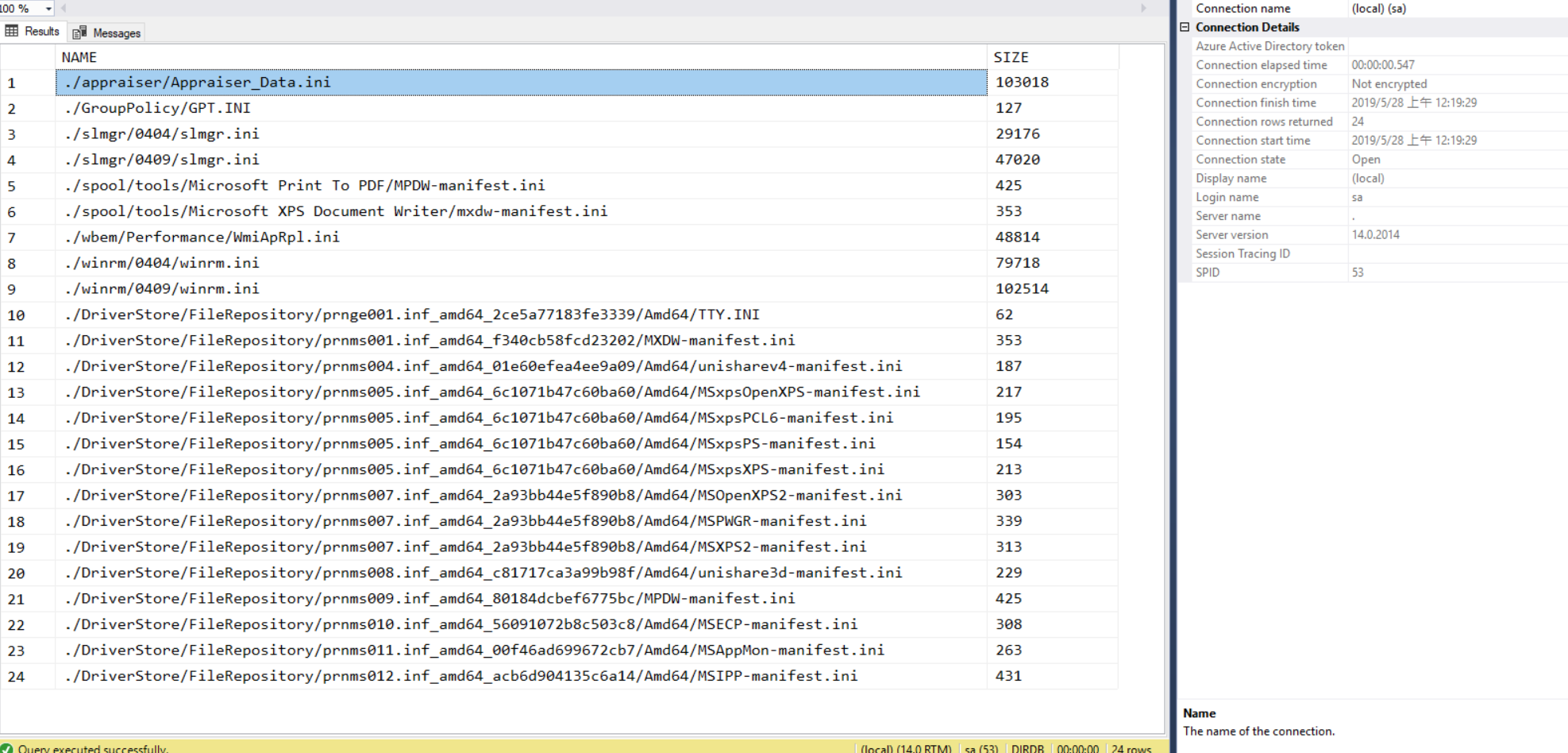
拿 DIR 指令 ( dir /s /b /a c:\windows\system32\*.ini ) 對照一下:
C:\Windows\System32>dir /s /b /a *.ini
C:\Windows\System32\PerfStringBackup.INI
C:\Windows\System32\tcpmon.ini
C:\Windows\System32\WimBootCompress.ini
C:\Windows\System32\appraiser\Appraiser_Data.ini
C:\Windows\System32\DriverStore\FileRepository\prnge001.inf_amd64_2ce5a77183fe3339\Amd64\TTY.INI
C:\Windows\System32\DriverStore\FileRepository\prnms001.inf_amd64_f340cb58fcd23202\MXDW-manifest.ini
C:\Windows\System32\DriverStore\FileRepository\prnms004.inf_amd64_01e60efea4ee9a09\Amd64\unisharev4-manifest.ini
C:\Windows\System32\DriverStore\FileRepository\prnms005.inf_amd64_6c1071b47c60ba60\Amd64\MSxpsOpenXPS-manifest.ini
C:\Windows\System32\DriverStore\FileRepository\prnms005.inf_amd64_6c1071b47c60ba60\Amd64\MSxpsPCL6-manifest.ini
C:\Windows\System32\DriverStore\FileRepository\prnms005.inf_amd64_6c1071b47c60ba60\Amd64\MSxpsPS-manifest.ini
(以下省略)
跟實際在本機下指令看到的結果一致,這項測試也算過關!
不過,從這裡開始,效能就出現差異了。效能問題最後再一起探討,我先記錄一下效能相關資訊:
執行時間: 00:00:00.547 (sec) 執行計畫 (Estimated Subtree Cost): 0.942181
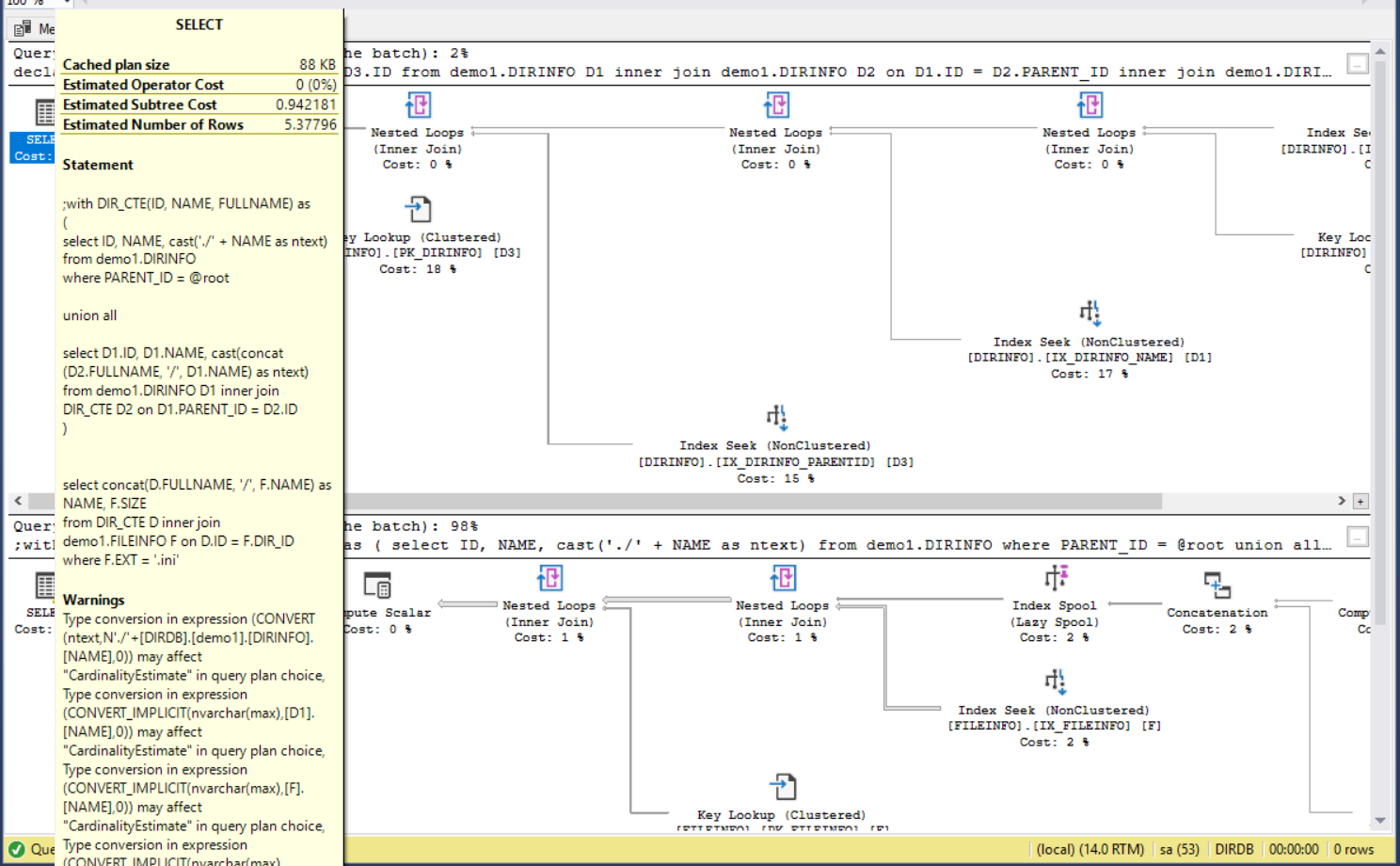
不過這幾個檔案就花掉 0.547 sec… 我換大一點的範圍再來搜尋一次看看;這次換成搜尋 c:\windows 下所有的 *.dll :
;
-- step 1, 找出 c:\windows 的 ID
ID
from
join
PARENT_ID
'
-- step 2, 建立 c:indows 下的所有 DIR LIST 清單 (CTE)
;with DIR_CTE(ID, NAME, FULLNAME) as
(
select ID, NAME, cast('' + NAME as ntext)
from demo1.DIRINFO
where PARENT_ID = @root
uni-on all
select D1.ID, D1.NAME, cast(concat(D2.FULLNAME, '', D1.NAME) as ntext)
from demo1.DIRINFO D1 inner join DIR_CTE D2 on D1.PARENT_ID = D2.ID
)
-- step 3, 依據 (2), 找出所有 (2) 目錄下, 附檔名為 .dll 的檔案及大小清單
select concat(D.FULLNAME, '', F.NAME) as NAME, F.SIZE
from DIR_CTE D inner join demo1.FILEINFO F on D.ID = F.DIR_ID
where F.EXT = ''
執行時間: 00:00:08.138 (sec) 執行計畫 (Estimated Subtree Cost): 3.09097
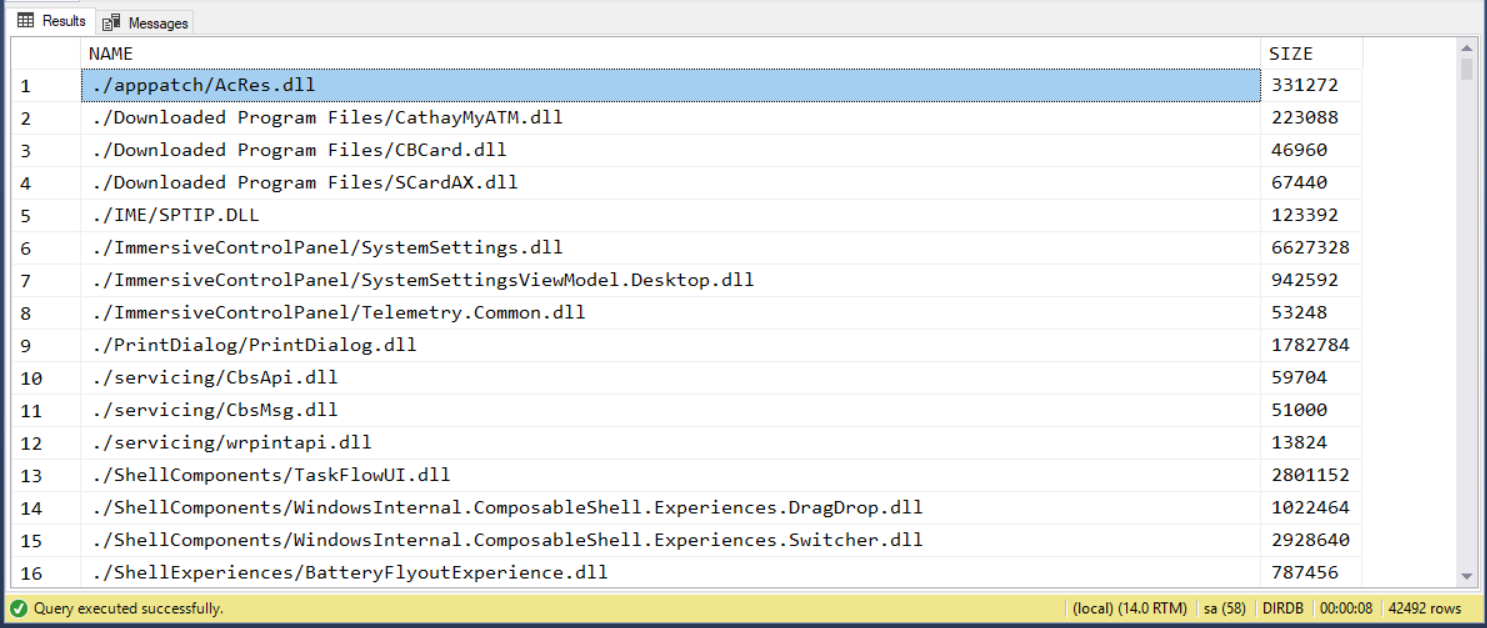
MSSQL 小記:
CTE 從 MS-SQL 2005 開始支援,而到了 MS-SQL 2008 則更進一步支援了 hierarchyid 這種欄位的型別,直接支援了樹狀結構的操作,處理這類結構的效能也比 CTE 來的好。不過我這篇不打算額外介紹這機制了,我的目的是讓 developer 多思考這類問題的解決方式,而非介紹 SQL SERVER 的特異功能。會介紹 CTE 已經是我的極限了,至少他只是在查詢語法上的支援,在不同的 DBMS 大都有類似對應的語法。我期望 developer 看完我這篇,會思考如何有效的靈活應用,不論是在 MS-SQL, Oracle, 或是 MySQL / Postgras …
參考資料:
- SQL Server (CTE): 黑暗執行緒: SQL 2005 T-SQL Enhancement: Common Table Expression
- SQL Server (HierarchyID): Rico技術農場: SQL SERVER hirearchy method
- Oracle (Connect By):
黑暗執行緒: ORACLE筆記-使用 CONNECT BY 呈現階層化資料
需求 3, 建立目錄
這種結構,就是以每個目錄上下層的相對關係為主來設計的,因此對於 tree 的異動 (搬移、刪除、建立) 都很直覺。來看第三個需求:
模擬
mkdir c:\windows\backup
建立目錄的需求挺容易的,三個欄位給對就結束了。直接看 T-SQL script:
;
-- step 1, 找出 c:\windows 的 ID
ID
from
join
PARENT_ID
'
-- step 2, 在 c:indows 下新增子目錄 backup
insert demo1.DIRINFO (PARENT_ID, NAME) values (@root, '');
select @@identity
執行時間: 00:00:00.028 (sec) 執行計畫 (Estimated Subtree Cost): 0.0500064
這種 insert 操作,其實閃一下就過去了。為了確認結果,我們用前面的 script, 查詢看看 c:\windows 的子目錄長啥樣。下列這段 SQL script 請依附在上面的 script 後面執行:
-- step 3, 查詢 c:\windows (ID: @root) 下的子目錄
asc
查詢結果:
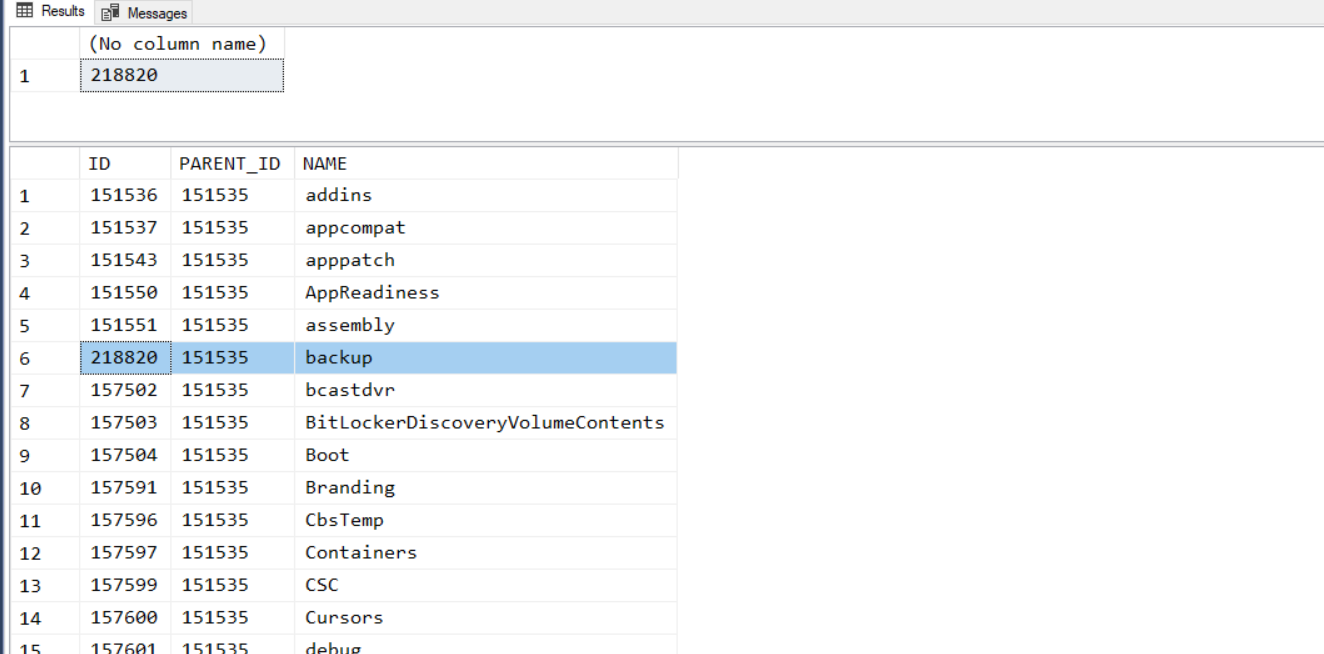
這題也輕鬆過關了! 接下來挑戰搬移目錄:
需求 4, 搬移目錄
模擬
move c:\users c:\windows\backup
這邊我特地挑了目錄搬移前後的階層會改變的範例。後面的範例就知道難搞了。一樣,基本上把要搬移的目錄,還有搬移的目的地目錄的 ID 找出來後,一行 update 指令就大功告成:
;
;
-- step 1, 找出 c:\windows\backup 的 ID (@destID)
ID
from
join
join
PARENT_ID
'
-- step 2, 找出 c:sers 的 ID (@srcID)
select @srcID = D2.ID
from
demo1.DIRINFO D1 inner join
demo1.DIRINFO D2 on D1.ID = D2.PARENT_ID
where D1.NAME = ''
-- step 3, 搬移 c:sers 目錄
update demo1.DIRINFO set PARENT_ID = @destID where ID = @srcID
-- step 4, 用 DIR_CTE 列出 c:的目錄列表
;with DIR_CTE(ID, NAME, FULLNAME) as
(
select ID, NAME, cast('' + NAME as ntext)
from demo1.DIRINFO
where PARENT_ID = @destID
uni-on all
select D1.ID, D1.NAME, cast(concat(D2.FULLNAME, '', D1.NAME) as ntext)
from demo1.DIRINFO D1 inner join DIR_CTE D2 on D1.PARENT_ID = D2.ID
)
select * from DIR_CTE
真正執行搬移的動作 (step 3): 執行時間: 00:00:00.026 (sec) 執行計畫 (Estimated Subtree Cost): 0.0232853
其中真正有異動資料的部分,只有 step 3 的那行 update 指令而已。 step 4 我是用前面範例介紹的 DIR_CTE,拿來當 DIR 的工具,把 c:\windows\backup 目錄下的子目錄列出來,證明搬移有成功執行而已。
這段 update 的執行計畫,Estimated Subtree Cost: 0.0232853
執行結果:
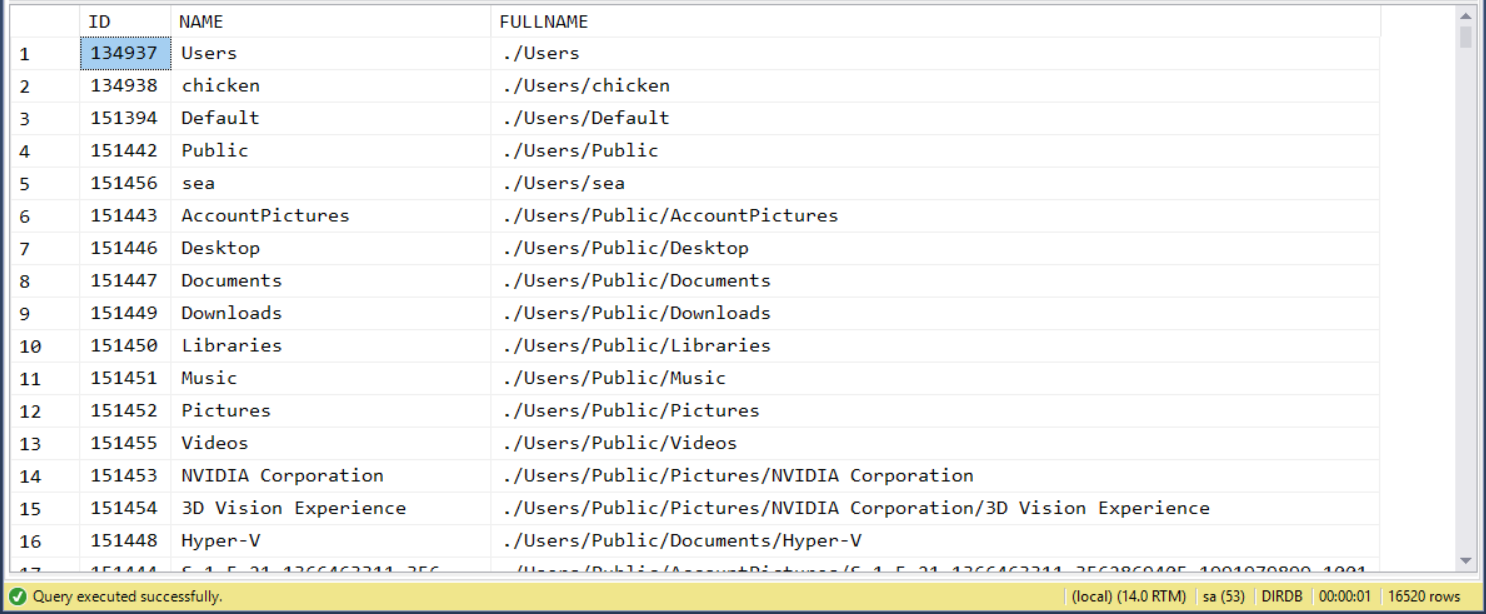
需求 5, 刪除目錄
接下來最後一關,刪除剛才建立且搬移的目錄:
模擬
rm /s /q c:\windows\backup
基本上,就是綜合題而已。查出 c:\windows\backup 下的所有檔案及子目錄,逐一刪除就好了。 我先留 c:\windows\backup 本身不刪除 (其實就多補一行 delete 就搞定了),這樣查詢刪除前後結果會比較清楚。
-- c:\windows
-- c:\windows\backup
-- step 1, 找出 c:\windows\backup 的 ID (@destID)
ID
from
join
join
PARENT_ID
'
-- step 1.1, 列出 c:indows 的所有子目錄 (刪除前)
;with DIR_CTE(ID, NAME, FULLNAME) as
(
select ID, NAME, cast('' + NAME as ntext)
from demo1.DIRINFO
where PARENT_ID = @root
uni-on all
select D1.ID, D1.NAME, cast(concat(D2.FULLNAME, '', D1.NAME) as ntext)
from demo1.DIRINFO D1 inner join DIR_CTE D2 on D1.PARENT_ID = D2.ID
)
select * from DIR_CTE
-- step 2, 刪除 c:ackup (@destID) 下的所有檔案
;with DIR_CTE(ID, NAME, FULLNAME) as
(
select ID, NAME, cast('' + NAME as ntext)
from demo1.DIRINFO
where PARENT_ID = @destID
uni-on all
select D1.ID, D1.NAME, cast(concat(D2.FULLNAME, '', D1.NAME) as ntext)
from demo1.DIRINFO D1 inner join DIR_CTE D2 on D1.PARENT_ID = D2.ID
)
delete demo1.FILEINFO where DIR_ID in (select ID from DIR_CTE)
-- step 3, 刪除 c:ackup (@destID) 下的所有目錄
;with DIR_CTE(ID, NAME, FULLNAME) as
(
select ID, NAME, cast('' + NAME as ntext)
from demo1.DIRINFO
where PARENT_ID = @destID
uni-on all
select D1.ID, D1.NAME, cast(concat(D2.FULLNAME, '', D1.NAME) as ntext)
from demo1.DIRINFO D1 inner join DIR_CTE D2 on D1.PARENT_ID = D2.ID
)
delete demo1.DIRINFO where ID in (select ID from DIR_CTE)
-- step 4, 列出 c:indows 的所有子目錄 (刪除後)
;with DIR_CTE(ID, NAME, FULLNAME) as
(
select ID, NAME, cast('' + NAME as ntext)
from demo1.DIRINFO
where PARENT_ID = @root
uni-on all
select D1.ID, D1.NAME, cast(concat(D2.FULLNAME, '', D1.NAME) as ntext)
from demo1.DIRINFO D1 inner join DIR_CTE D2 on D1.PARENT_ID = D2.ID
)
select * from DIR_CTE
刪除前 (截錄片段):
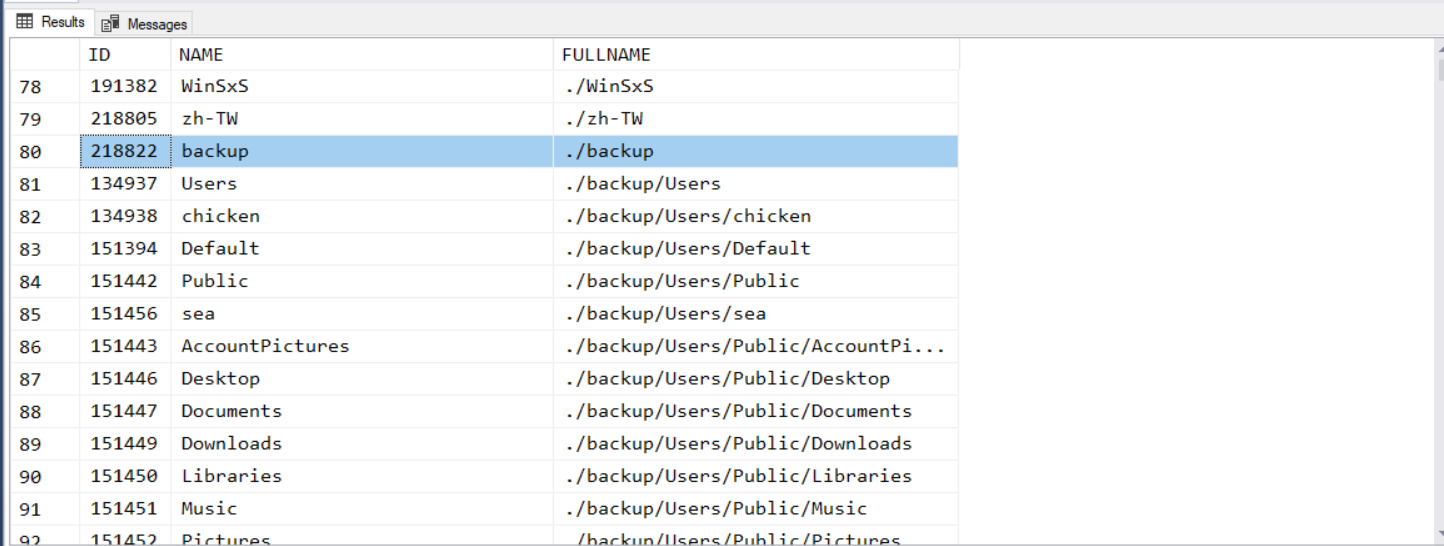
刪除後 (截錄片段):
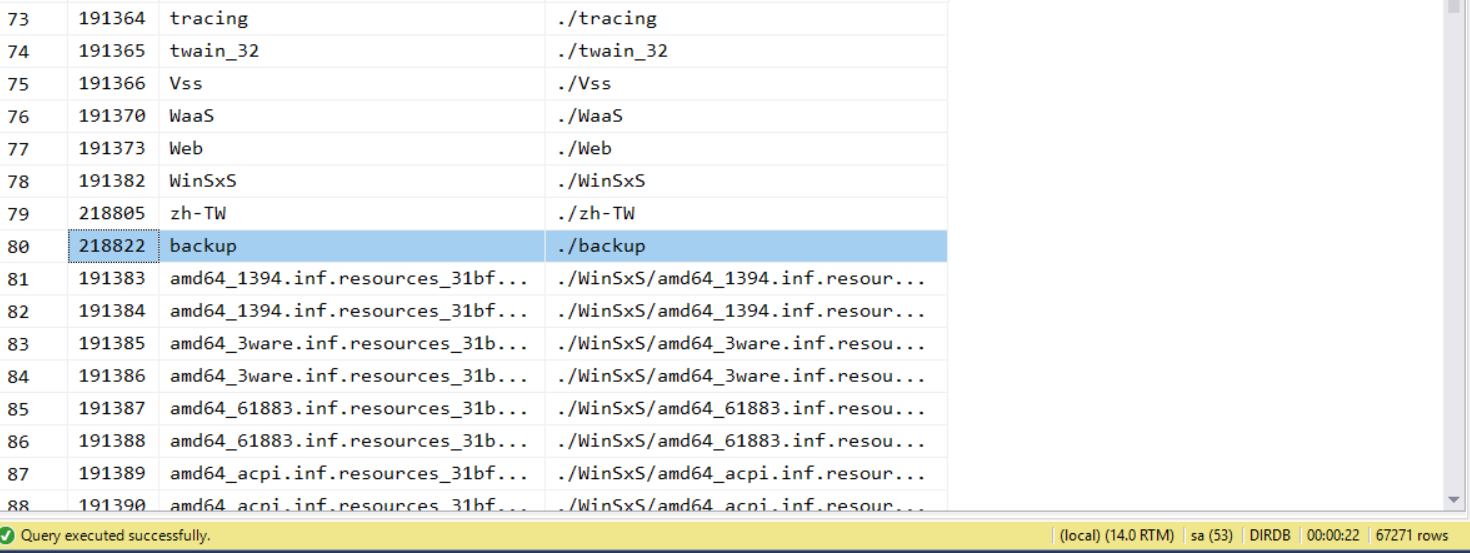
執行計畫:
- 刪除檔案 Estimated Subtree Cost: 2.57332
- 刪除目錄 Estimated Subtree Cost: 1.90982
總執行時間: 00:00:22.536 sec
小結
寫到這邊,開始有 fu 了嗎? SQL 這種很關聯式的資料庫,要處理 tree 這種東西,先天就是不大自然。你會發現很多語法其實都有點彆扭,寫起來就沒有那種一路到底的順暢感,尤其處理到不固定階層的地方腦袋都要轉好幾個彎,同時效能也不盡理想。CTE 只是解決遞迴的 query 不好寫的問題而已,他並沒有解決多層 self-join 帶來的效能影響。可以從前面的查詢計畫看到 cost, 搜尋的效能不算理想,若 CTE 還要再 join 其他 table, 甚至再進行 update / delete 的操作,效能問題就更明顯了。
因為這個方案,就是直接把寫 code 用的指標結構,原封不動的搬到 SQL schema 內來,因此原本用 programming language 的 recursive 處理方式,若 RDBMS 自身沒有支援 (例如查詢 ID 時, 幾層目錄你就要自己 self-join 幾次的作法),你就會發現很多 SQL 語法會囉嗦到你都看不下去。雖然 Oracle (CONNECT TO) / MS-SQL (CTE) 都有階層的查詢語法支援, 但是這些終究不是標準 SQL 語法,換句話說你使用 Entity Framework 這類 ORM, 或是你的 RDBMS 需要遷移到不同的系統時 (如 MS-SQL 換到 MySQL),這些 SQL query 就通通得重來…
因此,接下來的兩個解決方案,我就會開始拋開特定 DBMS 的語法支援,回歸到最單純原生的 RDBMS 操作技巧,開發者應該善用你的基礎知識,思考該如何透過 RDBMS 擅長的表格資料處理方式,來面對你的 Tree 結構。
方案 2, 開欄位記錄每一層目錄ID
方案一 的方式,雖然能漂亮的用 SQL 語法解決問題,不過有經驗的人大概都感覺得出來,這樣的效能實在有很大的改善空間。一般 DBA 在處理的資料量,都是要在幾千萬筆,甚至上億筆的數量級之下,查詢還要能在瞬間傳回來的。想像一下如果這些資料是你雲端硬碟的檔案清單,光是查詢就花掉 8 sec, 你一定不會覺得這服務速度很快很好用… (如果這是用在目錄同步的 API,我相信你會為了同步速度而抓狂…)
終究 RDBMS 擅長的不是這種遞迴的查詢,執行效能會耗費在多次重覆查詢的過程中,索引帶來的改善其實很有限。因此第二種方式,我試另一種極端的作法,放棄一些嚴謹的設計跟彈性,換來較理想的效能。這次我們來試看看,每一個階層都用一個欄位來代表的作法。
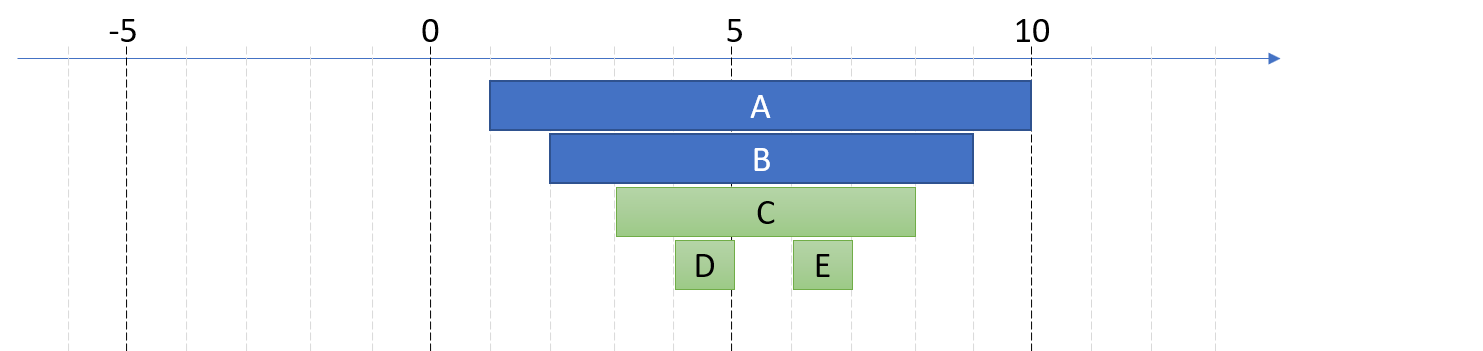
同樣先用簡單的 tree 來說明。用前面的圖來說明:
那麼資料表應該長這樣 (我簡化成五層就好):
| ID | ID1 | ID2 | ID3 | ID4 | ID5 |
|---|---|---|---|---|---|
| A | |||||
| B | A | ||||
| C | A | ||||
| D | A | C | |||
| E | A | C |
一樣,直接來看看轉化成 SQL table schema (範例資料 c:\ 目錄最深是 18 層, 我建立了 1 ~ 20 層的 ID 欄位):
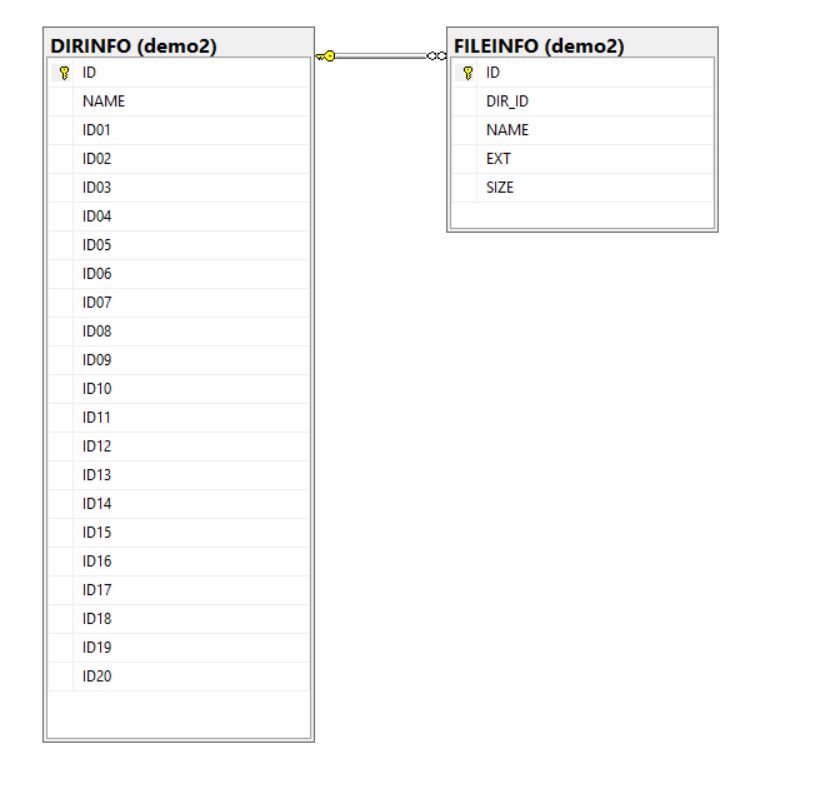
如果你對資料的一致性要求嚴格一點的話,接下來的步驟就麻煩了,你得對每一個欄位都設定 constraint … 沒錯,你決定建立 20 層欄位來應付將來的搜尋的話,你就得建立 20 次關聯性限制… 這邊容許我偷一點懶,我決定放棄建立關聯性限制了,我只針對搜尋的效能建立索引…。建立資料的部分我就略過了,以下是按照這種 schema 建立好的資料範例:
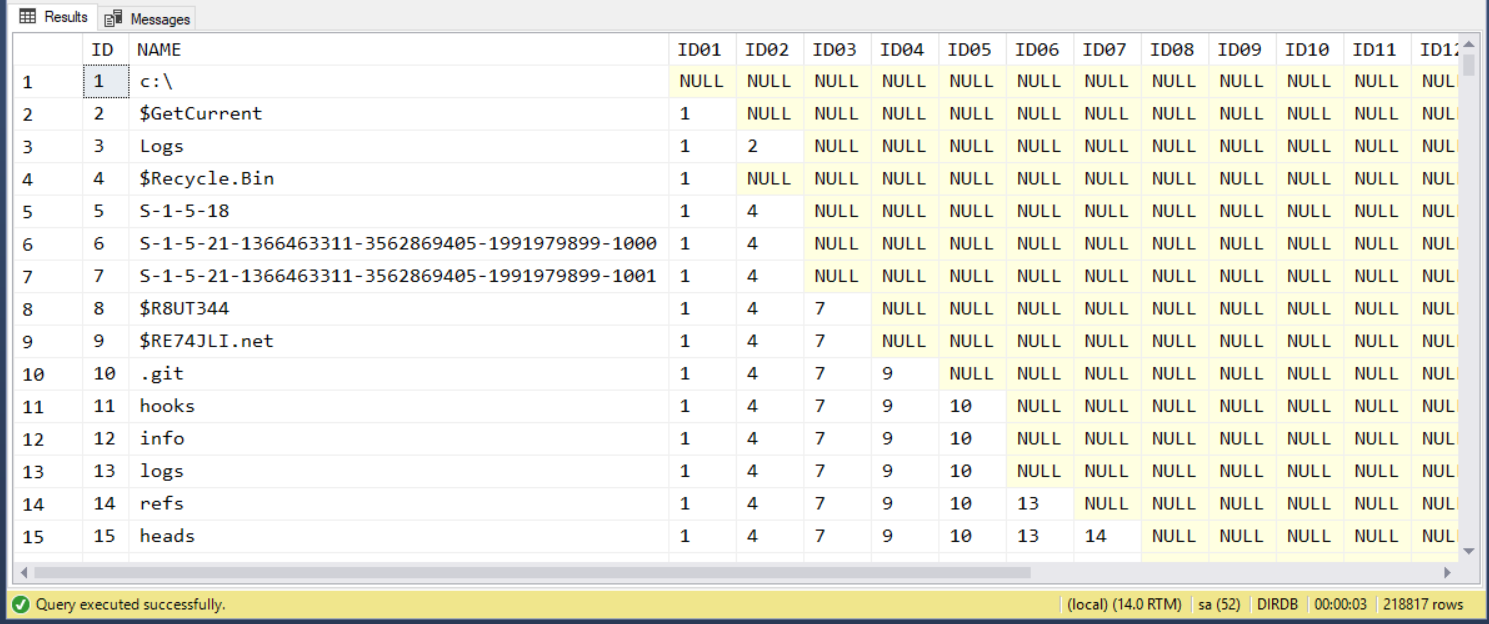
資料準備好了,同樣的來挑戰看看上述的需求:
需求 1, 查詢指定目錄下的內容
模擬
dir c:\windows的結果,列出c:\windows下的目錄與檔案清單,統計檔案的大小
這種結構,已經預先把目錄拆好了,按照階層順序逐步擺在 20 個欄位內。 為了簡化後面的查詢,我決定省略一些不重要的 script, 首先,先找到起始目錄 c:\, c:\windows, c:\windows\system32 的 ID, 後面的範例就直接填入 ID 了:
| ID | PATH |
|---|---|
| 1 | c:\ |
| 134937 | c:\users |
| 151535 | c:\windows |
| 189039 | c:\windows\system32 |
接下來就容易了,如果我們要找到直接掛在 c:\windows 下的所有子目錄,我會把查詢解讀成:
找到 ID01 是 1 (
c:\), 且 ID02 是 151535 (c:\windows), 且 ID03 ~ ID20 都是NULL的目錄。
其實這邊可以偷懶一點,只要我的資料建立時就是正確的話,ID02 = 151535 時,ID01 = 1 一定是成立的,同時 ID03 如果是 NULL,以後所有的 ID 也一定都是 NULL … 因此我的搜尋條件可以再簡化一點:
*
DIRINFO
NULL
查詢結果:
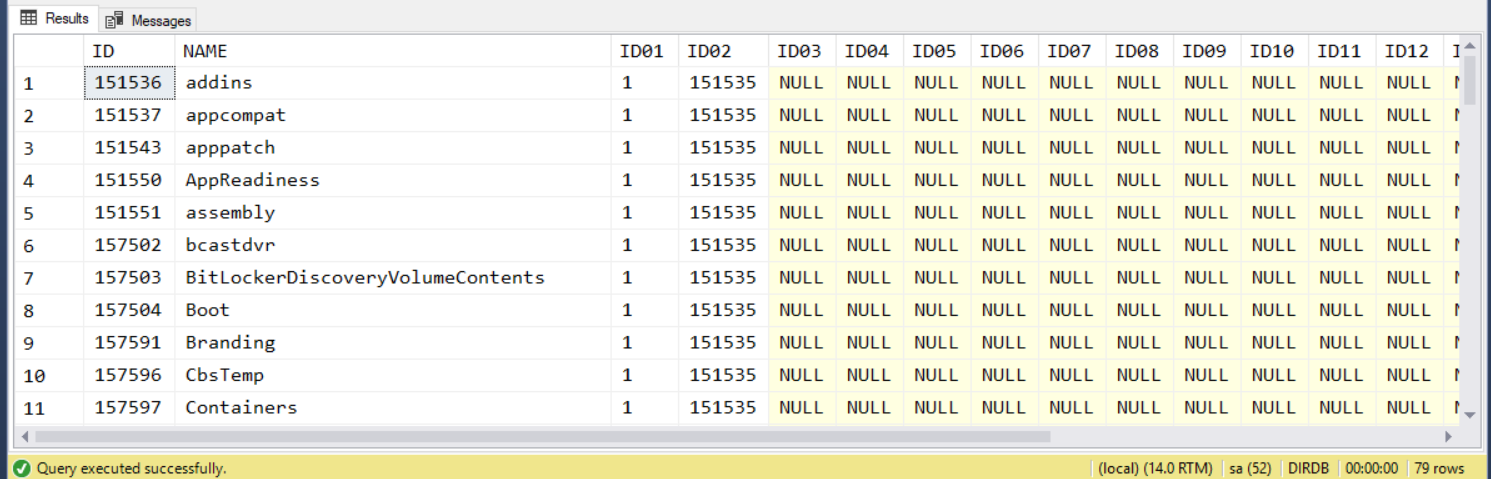
執行時間: 00:00:00.184 (sec) 執行計畫 (Estimated Subtree Cost): 0.0077312
要補上檔案也不是什麼難事:
*
FILEINFO
151535
查詢結果:
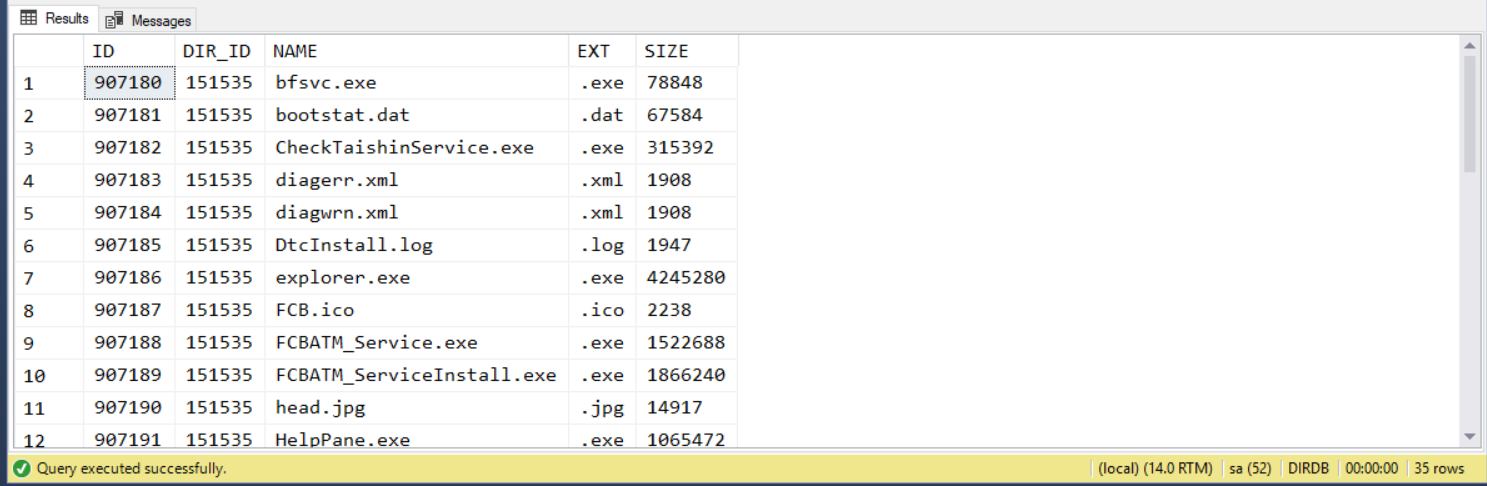
執行時間: 00:00:00.157 (sec) 執行計畫 (Estimated Subtree Cost): 0.213376
同前面的範例,整理一下格式:
from
(
NULL
uni-on
151535
asc
需求 2, 查詢指定目錄下的內容 (遞迴)
模擬
dir /s /b c:\windows\system32\*.ini, 找出所有位於c:\windows\system32目錄下 (包含子目錄) 所有副檔名為.ini的檔案清單
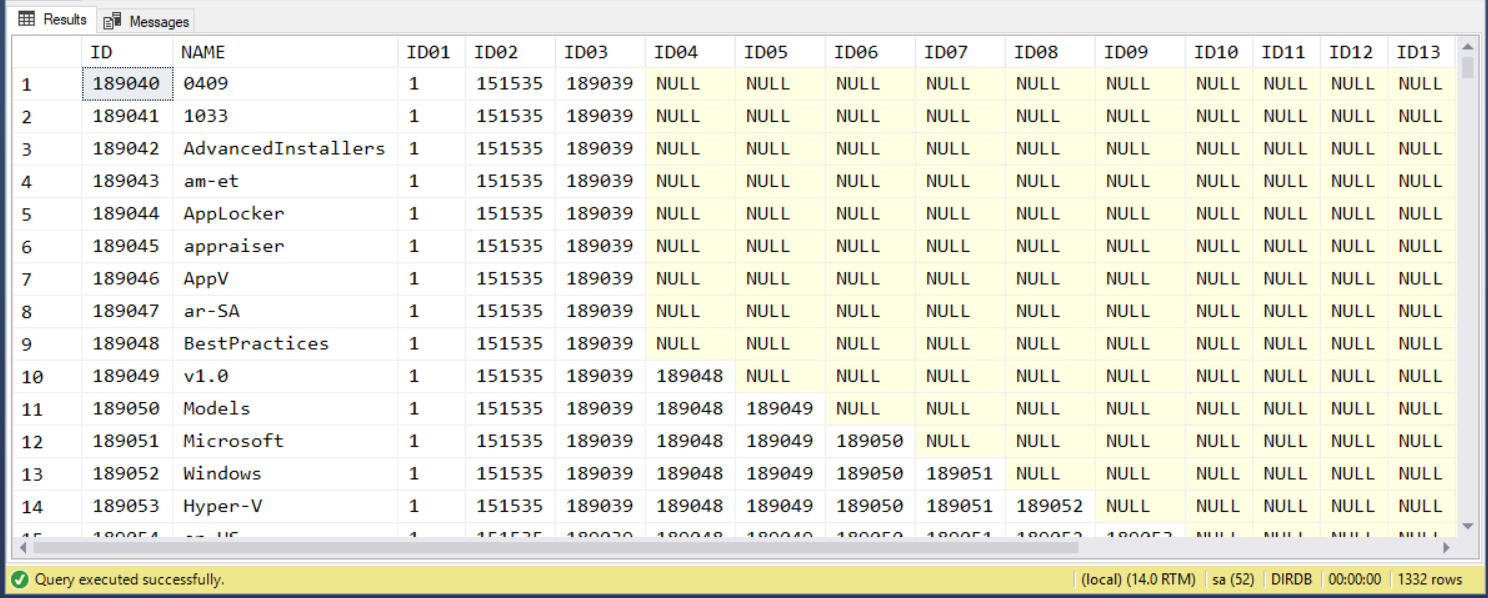
接下來,如果我們要遞迴的搜尋,在這案例反而更簡單了! 如果我要查詢 c:\windows\system32 下的所有子目錄,我的查詢只要這樣解讀:
找到 ID01 是 1 (
c:\), ID02 是 151535 (c:\windows) 且 ID03 是 189039 的目錄就可以了。
跟前面不同的是,你不再需要過濾 ID04 is NULL … ID04 是 NULL 代表這是直屬於 c:\windows\system32 下的子目錄,若 ID04 不是 NULL 則代表是再下一層的子目錄… 因此我要找 c:\windows\system32 下所有的子目錄清單,只要掠過 ID04 is NULL 條件:
*
DIRINFO
189039
查詢結果:
執行時間: 00:00:00.407 (sec) 執行計畫 (Estimated Subtree Cost): 0.0264708
目錄清單都出來了,要找到 c:\windows\system32\ 下所有子目錄的 *.ini 檔案清單,也不用太複雜的 SQL 就能搞定:
SIZE
ID
189039
查詢結果:
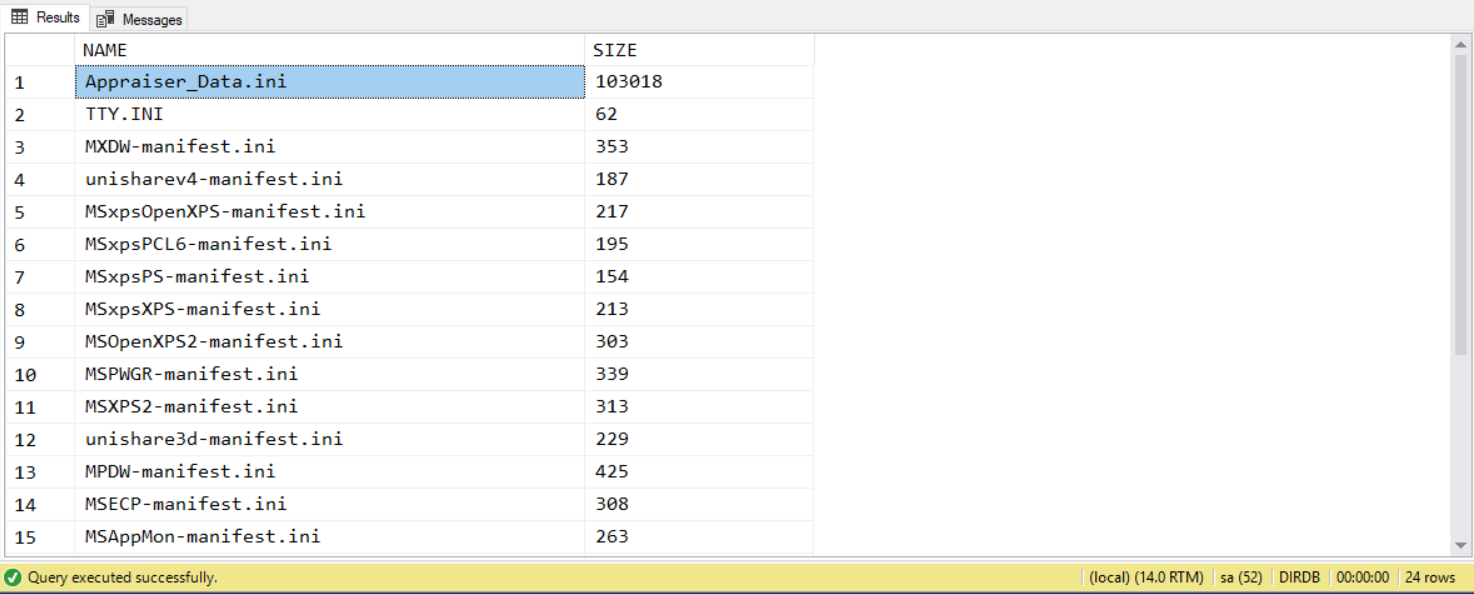
執行時間: 00:00:00.067 (sec) 執行計畫 (Estimated Subtree Cost): 0.18752
看到查詢效能跟語法上的差異了嗎? 整個困難度跟 方案1 完全是不同檔次的啊… 雖然 schema 的設計看起來蠢了一點 (好吧,我覺得非常蠢),但是不得不說在效能跟查詢的困難度上來說是大勝啊!
難道方案1就一無是處嗎? 這也未必,我們繼續往下看…
需求 3, 建立目錄
模擬
mkdir c:\windows\backup
同樣的例子,如果我們要模擬 mkdir c:\windows\backup, 這方案的 schema 設計下應該怎麼做:
)
identity
查詢結果: 218818 執行時間: 00:00:00.117 (sec) 執行計畫 (Estimated Subtree Cost): 0.0400054
這邊討厭的地方在於: 階層的不同,直接影響你的 code 結構。SQL 不像其他語言有那麼多彈性,你如果不想動用到 dynamic sql 動態產生語法, 那麼很抱歉,這查詢無法讓你寫成固定的 SQL + 參數的方式執行。或者你就必須寫出很不精簡的語法,例如帶 ID01 ~ ID20 全部的參數,不需要的部份給 NULL …
如果你妥協了,改用 dynamic sql 用程式碼湊出要執行的 SQL 語法,那這樣很容易就會寫出 SQL injection 漏洞的程式碼… 不過,這問題還算好解決,不算很嚴重的缺點。我們繼續看下一個例子…
需求 4, 搬移目錄
模擬
move c:\users c:\windows\backup
同前面的 方案1,接著我們來模擬 move c:\users c:\windows\backup :
這邊開始有點令人抓狂了,我拆成幾個分解動作…
- 找出所有
c:\users下的子目錄 - 把 (1) 的 ID 都往右平移一層,例如
ID19搬到ID20,ID18搬到ID19… - 把
ID01,ID02,ID03填入 1(c:\), 151535(c:\windows), 218818(c:\windows\backup)
忍不住再抱怨一次,寫成 SQL 實在有點醜…
DIRINFO
set
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
-- 以上為 shift right
-- ID03 => c:\windows\backup
-- ID02 => c:\windows
-- ID01 => c:\
-- c:\users
查詢結果:
執行時間: 00:00:00.758 (sec) 執行計畫 (Estimated Subtree Cost): 18.3011
這查詢看起來真是有點噁心… 最討厭的是 shift right 的動作也一樣,也很難寫成 store procedure…。至於這指令有沒有搬移成功? 用前面的技巧查看看:
dir c:\windows\backup (218818)
218818
查詢結果:
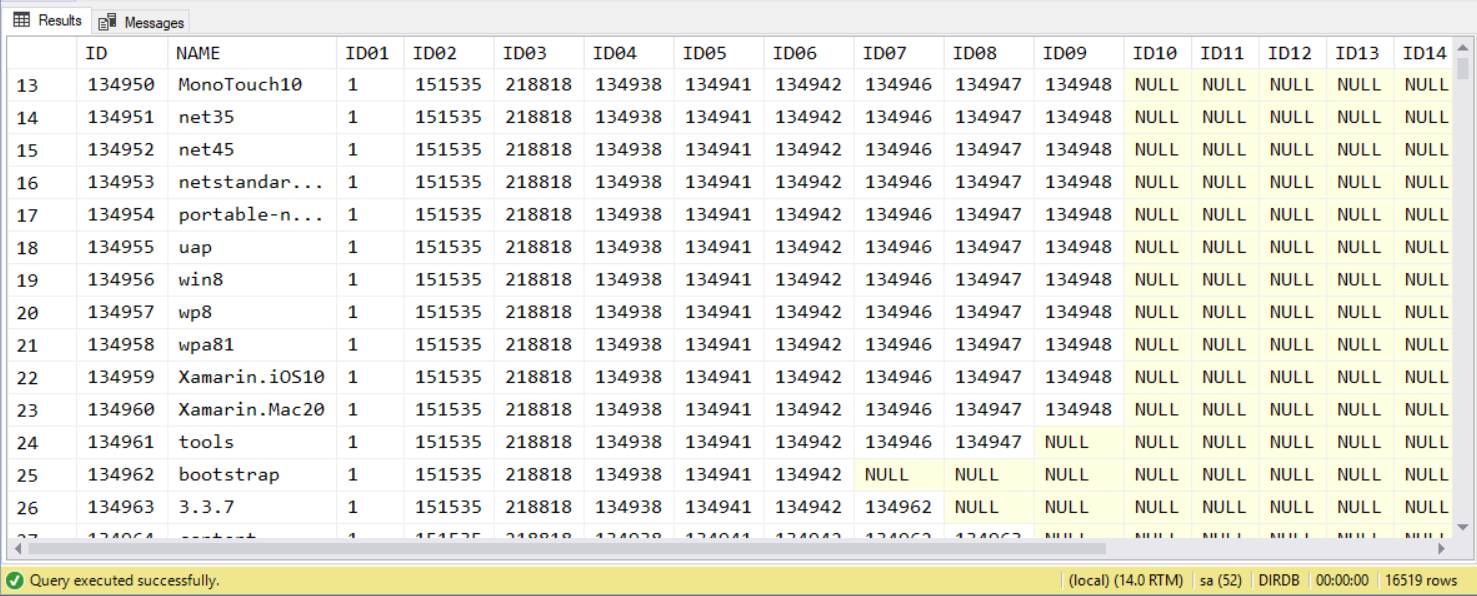
好吧,雖然噁心但是至少也是有效率的完成任務了。總檢討後面再說,來看最後一個需求…
需求 5, 刪除目錄
模擬
rm /s /q c:\windows\backup
延續前面案例,如果我要刪除 c:\windows\backup 下的子目錄跟檔案… 這反而沒什麼困難,先查詢所有的子目錄跟檔案,然後刪除即可。
不囉唆直接看 SQL 指令 (我一樣保留 c:\windows\backup 目錄本身,方便稍後驗證結果) :
del /s c:\windows\backup
-- step 1, delete files
)
-- step 2, delete folders
218818
(刪除檔案部分) 執行時間: 00:00:18.962 (sec) 執行計畫 (Estimated Subtree Cost): 143.985
(刪除目錄部分) 執行時間: 00:00:01.343 (sec) 執行計畫 (Estimated Subtree Cost): 13.7447
方案 2 小結
寫到這邊快昏倒了,後面更新 tree 的操作真是令人反胃啊,一直很強調程式碼結構跟可讀性的我,要我寫這種看起來就很不乾脆的 SQL script 真是痛苦,總算把這段範例寫完了。
看完方案 2 的 schema 設計,跟各種 tree 的操作,有看出兩個方案的差異了嗎? 以我的觀點來說,這兩種方案各有優點:
方案一的設計,明顯搭配資料結構課本講的 tree 的結構,所有結構都是相對的,因此很容易做搬移的操作;相對的 tree 的查詢需要用到遞迴,效能就拉不起來,相對的 SQL query 也不容易撰寫 (如果你不用 CTE 這類指令來簡化的話,問題會更惡化)。這是一種針對 tree 異動最佳化的設計。
方案二的設計則是採取另一個面向。我把 ID01 ~ ID20 這很醜的欄位,視為 developer 自行維護的 index 來看待。這些索引,在應付各種 tree 的查詢都能發揮最大功效 (你可以明顯看出查詢的速度與語法的優勢)。不過索引是需要花力氣維護的,因此這些資料維護的複雜度,在 “搬移” tree node 時就完全暴露出來了。這是一種針對 tree 搜尋效率極度最佳化的設計。
我想,做過這樣的比較,大部分人都會想:
既然這樣,我不需要 tree 搬移的功能的話 (通常組織圖、或是網站的選單、購物網站的分類等等都不常見到搬移的操作),絕大部分都是查詢,我當然是選擇方案二啊…
不過,這方法雖然又蠢又有效,但是不同階層的查詢,必須準備不同的 SQL script 這限制實在很礙眼.. XD。 接下來我要介紹一個過去十幾年來,幾乎各個方面都是完美的設計: Nested Set Model (鋪梗鋪真久)..
方案 3, 標記涵蓋範圍
這方法我在 2003 年的時候,花了不少功夫在研究出來的 (後來才發現也有人做出類似的作法了)。主要想法是:
如果我能自己額外維護索引,把某些資訊預先準備好,讓我在做 tree 的不限階層搜尋時,能極大化的使用 RDBMS 的威力,同時又能兼顧語法的簡潔與標準化,那我該怎麼設計索引?
我開始想到能否直接忘掉階層這件事,改用 “範圍” 的觀念來想? 階層越上層,剛好代表涵蓋的範圍越廣而已;如果我把整棵樹攤平壓在座標軸上,上層的範圍必須涵蓋所有下層的範圍,那麼每個 node 只要標上涵蓋範圍的起點跟終點就可以了。這個想法收斂之後,就是這個方案要講的。後來也才意外發現,原來 wiki 上也有類似的作法,而且還有個名字: Nested Set Model。
回憶一下當年這樣做的動機,順便提一下當年勇 XDD。當年碰到前系統用 Tamino, 一套由德國軟體公司 Software AG 開發的 Native XML database (其實就是現在的 NOSQL, 很多觀念都很類似);當年研究所是 Database Lab, 很多論文在研究 OODB, 撇開物件的行為 (method) 怎麼儲存,XML database 就已經解決大部分 OODB 的問題了,近年來流行的 NOSQL 也是這樣演進過來的,只是 XML 逐漸被 JSON 替代而已。
會研究 Tamino 是因為 XML 在當時被大量用在處理數位學習的各種資料交換。這個產業的資料定義大都用 XML 為基礎建構起來的,理所當然的資料庫也選擇 XML database 是最合適的。無奈當時這觀念還是太前衛,許多企業 IT 碰到這聽都沒聽過的 database, DBA 沒有能力維護,我們的解決方案就很難打入企業的採購案內…
於是在將系統轉移到 MS-SQL 過程中,我碰到很多必須把 TREE 轉移到 MS-SQL 的情境。這個 Nested Set Model 就是我在那時看到的技巧。我只能說發明他的人實在太聰明了,在每個節點加上 left / right 左右兩個索引,就能夠很完美的用 SQL 擅長的 Set Operation (就是 SELECT 指令) 對 TREE 的資料結構做各種操作,完全沒有跨不同的 programming model 帶來的隔閡。
我同樣用前面的 tree 來說明一下:
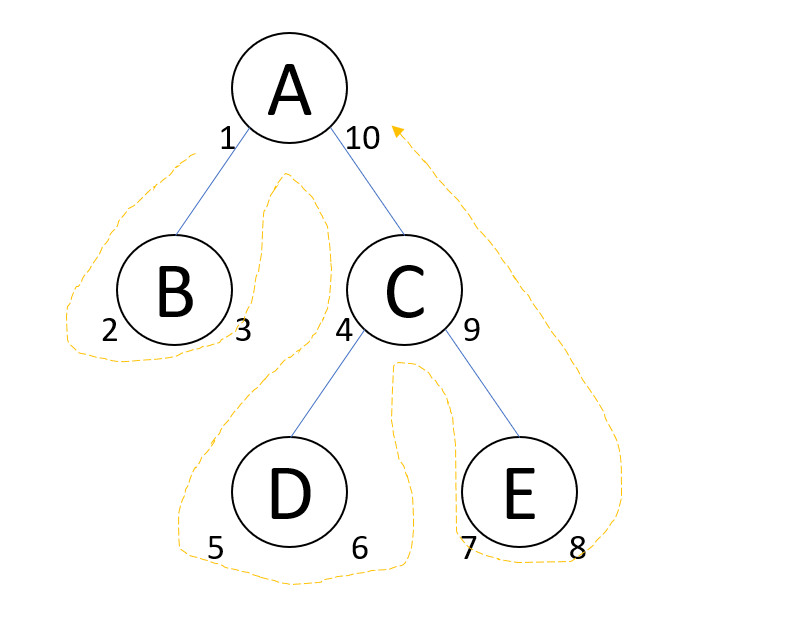
標上 left / right 的資料:
| ID | LEFT | RIGHT |
|---|---|---|
| A | 1 | 10 |
| B | 2 | 3 |
| C | 4 | 9 |
| D | 5 | 6 |
| E | 7 | 8 |
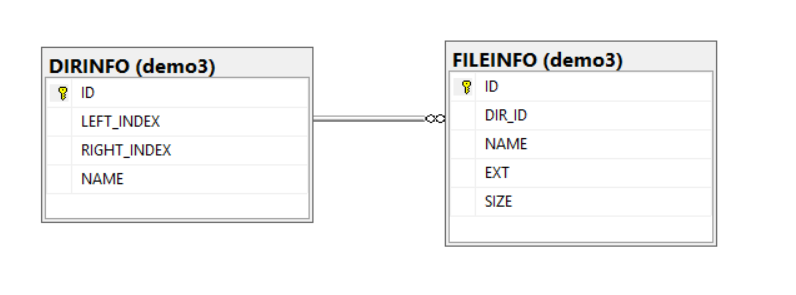
整個完整的 database diagram 大概長這樣:
這 left / right index 怎麼標出來的? 看看圖上標示的黃色箭頭… 基本上就是按照 depth first traversal 的方式走完每個節點。每個節點第一次被走到的時候就按順序標上 left,繞了一圈回到這個節點後再標上 right.. 這時 left / right 就代表這個結點在座標軸上涵蓋的範圍了。因為 depth first traversal 的規則,每個 node 底下的 nodes 都走完後一定會回來這個 node, 因此按照順序標上流水號,就成為這個結果了。這個 left / right index 可以同時代表多個意義,除了 “包含” 的關係之外,每個 node 一定都會佔掉兩個空間,因此只要 index 有維護好,都是連續整數的話,left / right 的數值差異就可以代表子節點的個數,你想計算子節點的各數時連查都不用查,直接 (right - left - 1) / 2 就可以得到答案了。
沒仔細想的話,光是看到這堆數字大概丈二金剛摸不著頭腦吧! 這是為 tree struct 精心設計的 index, wiki 上用了另一種視角來看這個結構。看一下 wiki 上的另一個例子:
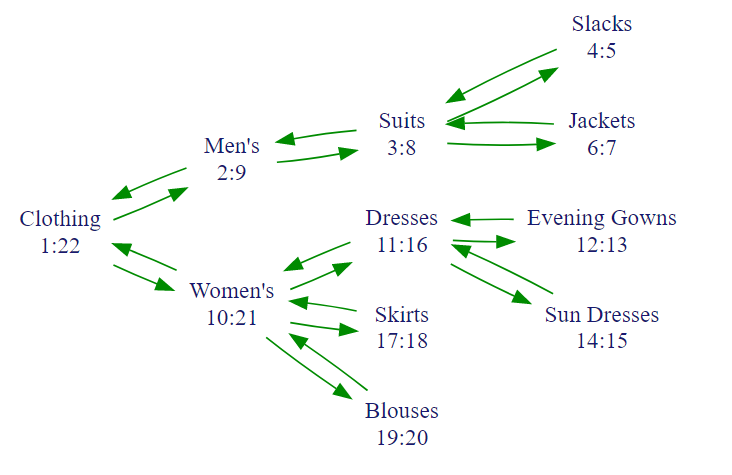
把標上的 index 呈現在數線上:
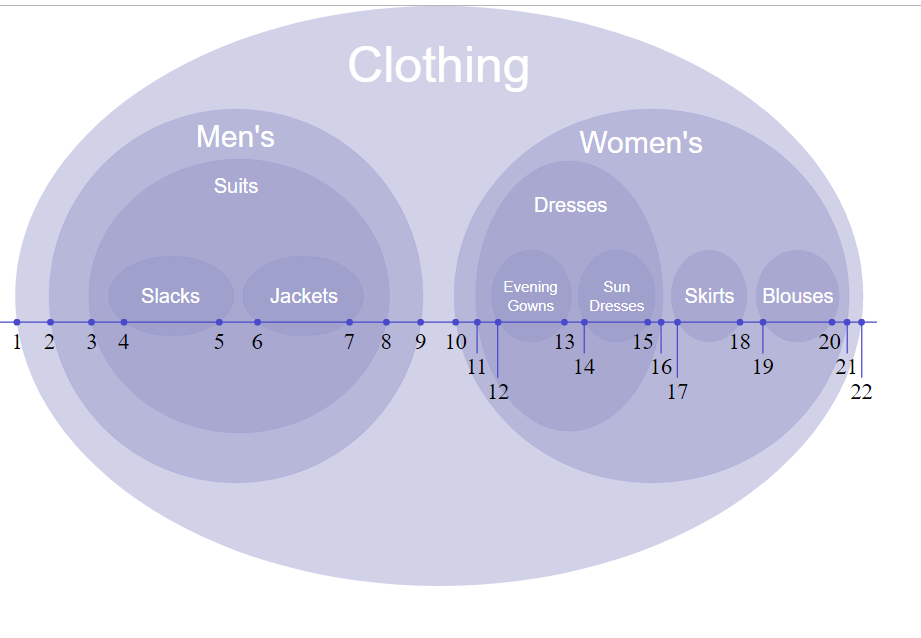
用實際的例子來說明上面的觀念吧。看出這標號的用意了嗎? clothing 的標記是 left:1, right:22, 代表所有 left, right 被包圍在 1 ~ 22 之間的都是他的子節點。搞懂規則後,只要你能在 tree 節點有異動時維護好這些 left / right index, 你會發現 tree 的各種操作會變的非常容易 (而且很容易對應到 SQL 的操作)。
舉個例子來說:
- 要找出 clothing(1,22) 所有的子節點,只要查詢:
select * from TREE where 1< left and right < 22; - 要計算 clothing(1,22) 底下有多少節點,只要:
set @total_nodes = (22 - 1 - 1) / 2;;
有沒有很神奇? 透過這樣的索引,查詢時你連階層的問題都不需要傷腦筋,自然沒有 SQL 難維護的問題了。簡單先介紹到這裡,實際的範例我們還是回到我的 c:\ 清單,實際走過這五個需求,看看這樣的 nested set model 應該怎麼處理。
同樣的,為了簡化後面的查詢,後面的範例就直接填入 ID 了 (L/R index 我也先標好):
| ID | NAME | LEFT | RIGHT |
|---|---|---|---|
| 1 | c:\ | 1 | 437634 |
| 134937 | c:\users | 269872 | 302911 |
| 151535 | c:\windows | 303068 | 437609 |
| 189039 | c:\windows\system32 | 378075 | 380740 |
需求 1, 查詢指定目錄下的內容
模擬
dir c:\windows的結果,列出c:\windows下的目錄與檔案清單,統計檔案的大小
簡單的說,這需求的查詢條件要想像成這樣:
找出所有 PARENT 底下的 CHILD, 排除 PARENT 跟 CHILD 中間存在任一個 MID 結點的清單…
有點繞舌? 直接來看看 SQL 查詢:
*
RIGHT_INDEX
exists
(
*
M
RIGHT_INDEX
RIGHT_INDEX
ID
)
查詢結果:
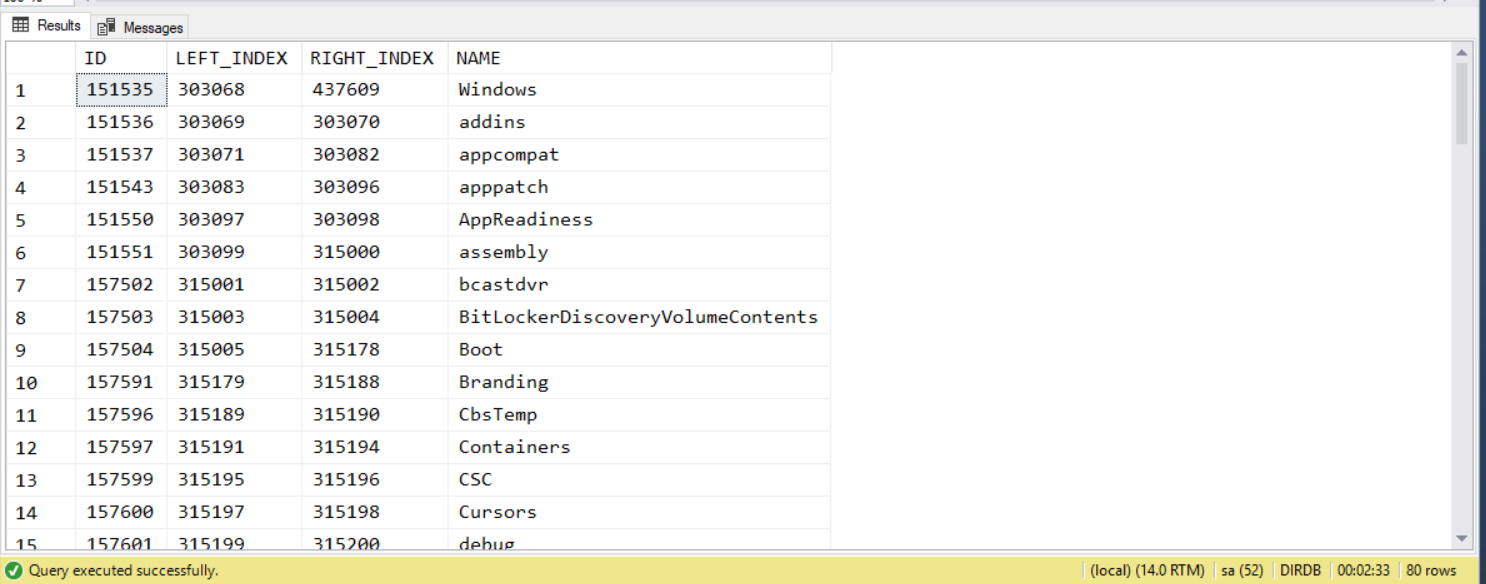
執行時間: 00:02:33.591 (sec) 執行計畫 (Estimated Subtree Cost): 0.941395
這查詢看起來有點蠢,把目標節點(P)所有的子節點(C)都找出來,然後排除中間有其他節點(M)的部分…
這我覺得有點矯枉過正了。WIKI 的範例是額外加上 DEPTH 這個索引 (一樣你要在 tree 異動時自己維護這欄位)。我自己專案實作則是合併 方案一 的 PARENT_ID,作法比較直覺。如果你像我一樣額外維護 PARENT_ID,那這個查詢的效能就會跟方案一一樣快跟簡潔。
至於格式化輸出的部分就省了,這邊完全跟前面的範例一樣,join FILEINFO 即可。
需求 2, 查詢指定目錄下的內容 (遞迴)
模擬
dir /s /b c:\windows\system32\*.ini, 找出所有位於c:\windows\system32目錄下 (包含子目錄) 所有副檔名為.ini的檔案清單
這結構的強項來了。如同前面介紹的一般,只要透過 LEFT / RIGHT 包圍的範圍來查詢就可以得到答案:
*
DIR_ID
380740
查詢結果:
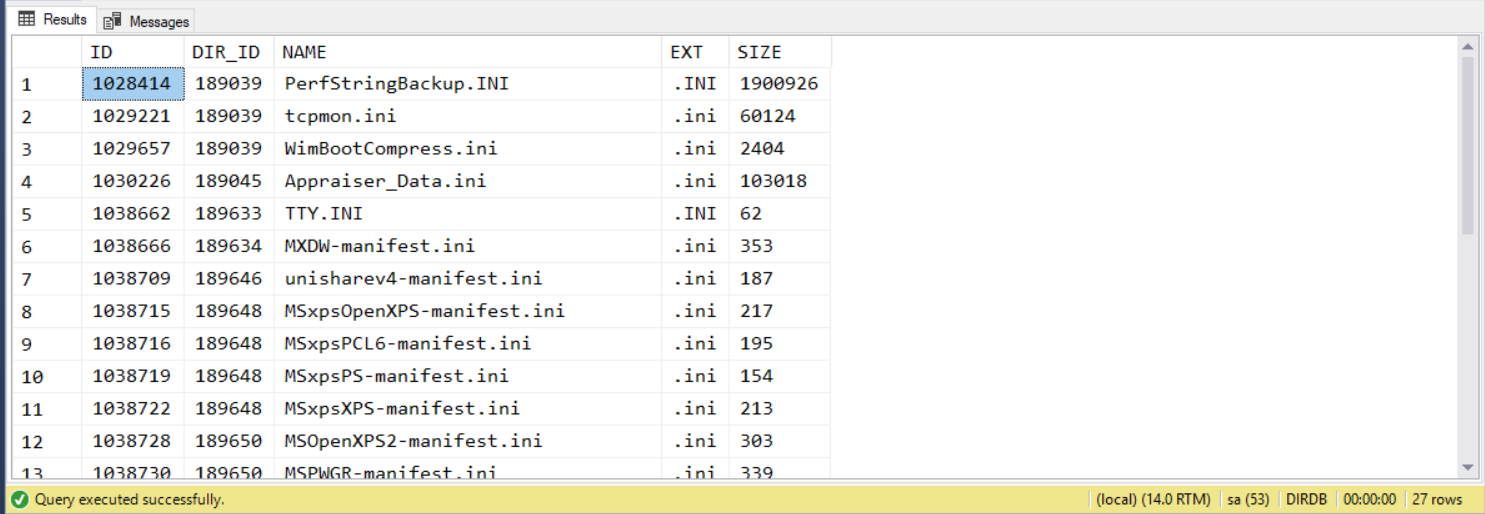
執行時間: 00:00:00.173 (sec) 執行計畫 (Estimated Subtree Cost): 0.167235
對比 方案一,如果也試著查看看 c:\windows\ 下的 *.dll, 看看結果:
*
DIR_ID
437609
查詢結果:
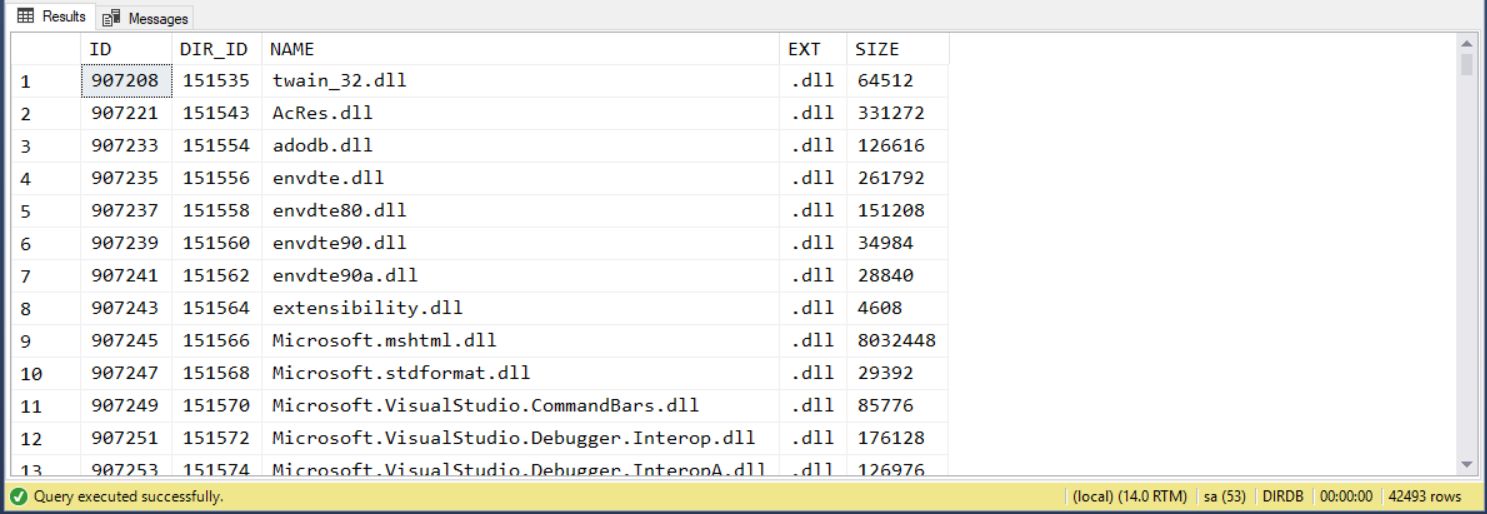
執行時間: 00:00:00.836 (sec) 執行計畫 (Estimated Subtree Cost): 10.7832
看出 方案三 特別的地方了嗎? 沒有 方案一 糟糕的效能;幾乎跟 方案二 同等級秒返的效率,但是查詢的語法卻不會像 方案二 那樣隨著層級改變,難以寫成 store procedure, 索引固定為 LEFT_INDEX / RIGHT_INDEX 兩個欄位 (不像 方案二 要 20 個欄位,你還無法預期要對哪個欄位下過濾條件)。這樣的結構大幅簡化了查詢的語法,完全可以將它放到 store procedure, 搭配參數即可執行。
當然,如果要把目錄跟檔案混在一起並且格式化輸出也不是難事:
from
(
437609
uni-on
SIZE
DIR_ID
437609
asc
查詢結果:
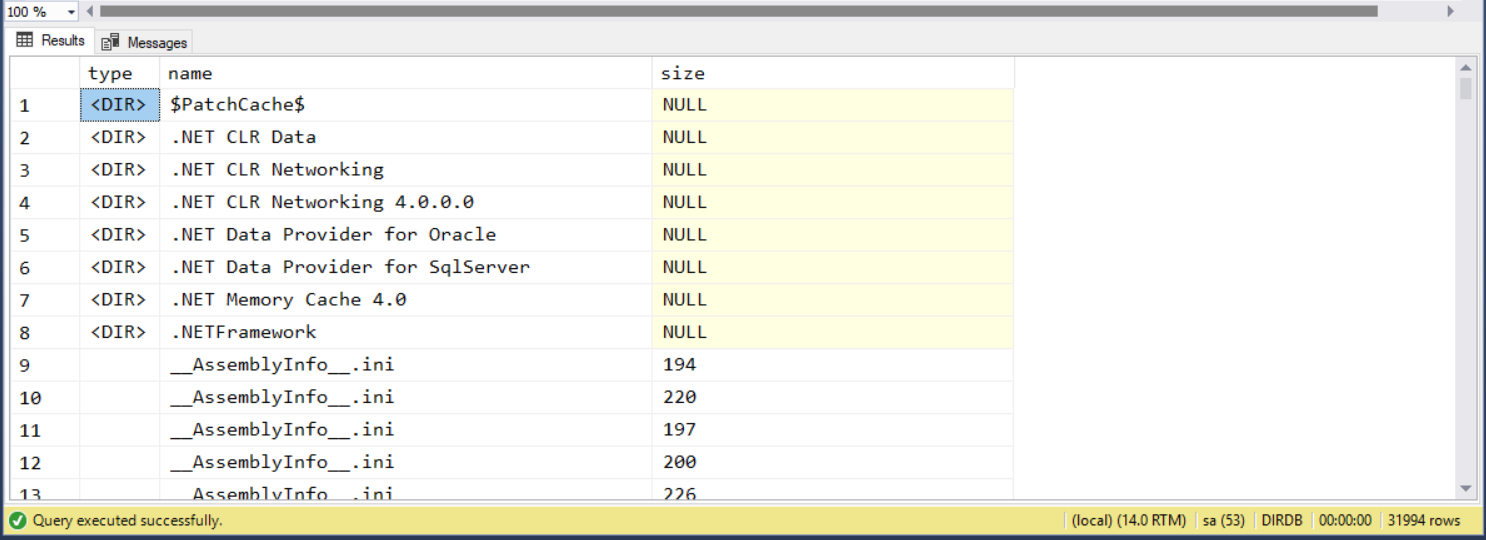
執行時間: 00:00:00.546 (sec) 執行計畫 (Estimated Subtree Cost): 4.08984
需求 3, 建立目錄
模擬
mkdir c:\windows\backup
同樣的例子,如果我們要模擬 mkdir c:\windows\backup, 這方案的 schema 設計下應該怎麼做:
回到 wiki 那張用 “涵蓋範圍” 觀念想像的圖來思考,建立一個目錄,就是插入一個節點,然後插入點右邊的所有 index 都 +2 (右移兩位) 就好了.. 直接來看 SQL:
;
;
-- step 1, 在 303068 騰出兩個位子,把所有 right_index > 303068 的數值都 +2
;
-- step 2, 在 303068 騰出兩個位子,把所有 left_index > 303068 的數值都 +2
;
-- step 3, 空出的兩個 index 就保留給插入的新目錄 c:\windows\backup
);
Step 1: 執行時間: 00:00:01.343 (sec) 執行計畫 (Estimated Subtree Cost): 7.39088
Step 2: 執行時間: 00:00:02.017 (sec) 執行計畫 (Estimated Subtree Cost): 29.6923
Step 3: 執行時間: 00:00:00.017 (sec) 執行計畫 (Estimated Subtree Cost): 0.0400054
查一下目錄是否有成功的被建立起來:
;
;
;
查詢結果:
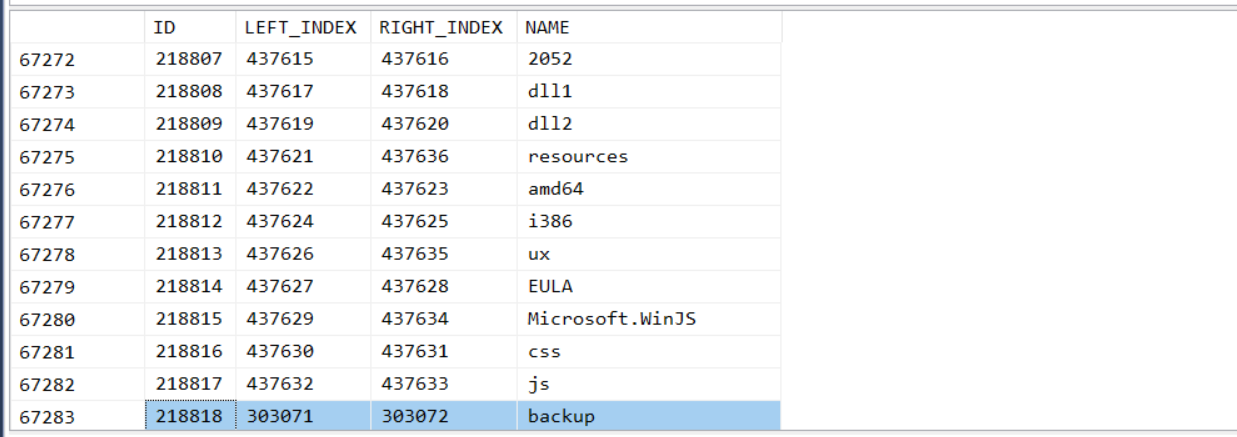
新增的目錄 ID: 218822
需求 4, 搬移目錄
模擬
move c:\users c:\windows\backup
同前面的方案1,接著我們來模擬 move c:\users c:\windows\backup …
動手之前,再來看一次該怎麼拆解 tree node 搬移的動作。回到前面說明用的圖:
我把它換成 wiki 的看法,在數線上面重畫一次這個 tree:
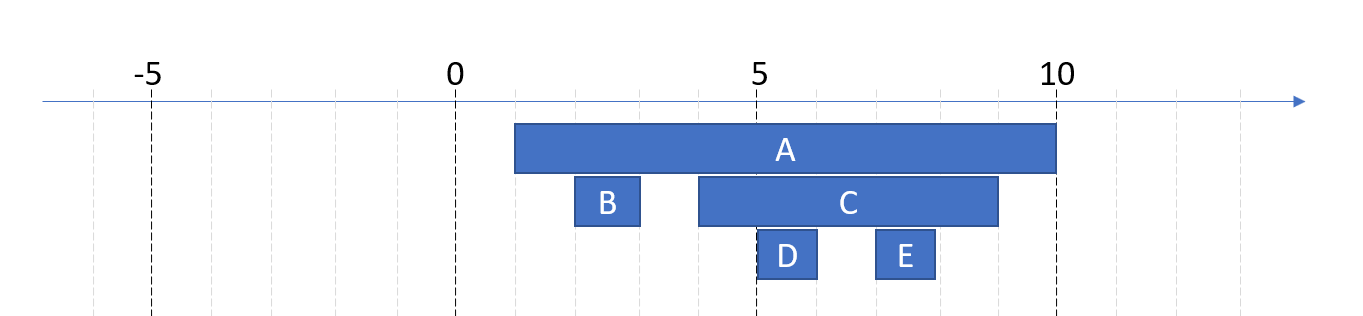
視覺化之後就很容易了解了。每個方框就是個 node, 上面的 node 寬度一定會完全涵蓋底下的 nodes, 同一層的 nodes 彼此不會重疊。接著用這種結構圖來說明一下搬移的步驟。其實步驟很簡單,就是兩個區塊之間的挪移而已。只是挪移的過程會卡來卡去的很麻煩,所以我用 0 以下的空間 (負數) 當作暫存區,先把要搬移的 nodes (C, D, E) 搬到暫存區, 然後把其他的 nodes 先調整大小,把目標 node (B)下的空間騰出來,最後再把搬到暫存區的 nodes (C, D, E) 搬回來就結束了。
直接來看分解步驟 (綠色代表這個步驟異動的部分):
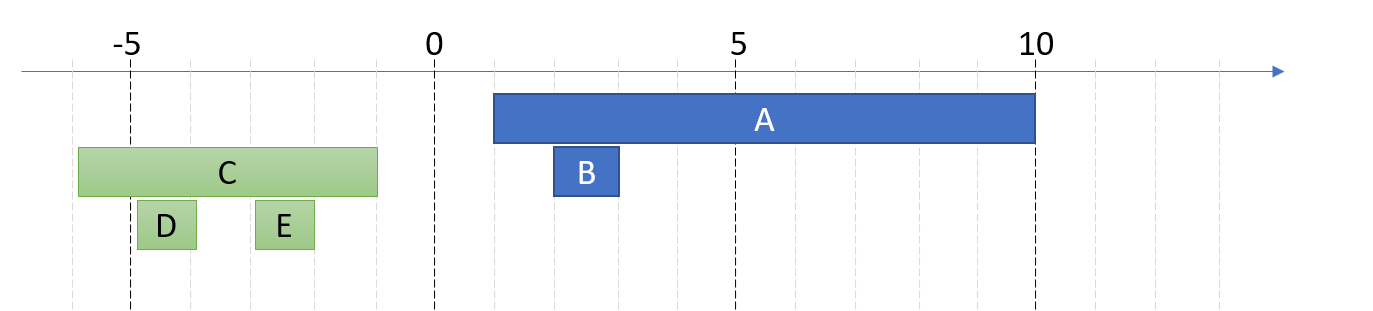
被搬移的 nodes 搬到暫存區:
C, D, E 都往左 shift 到全部的 index 都為負數為止。經過計算全部都位移 -10
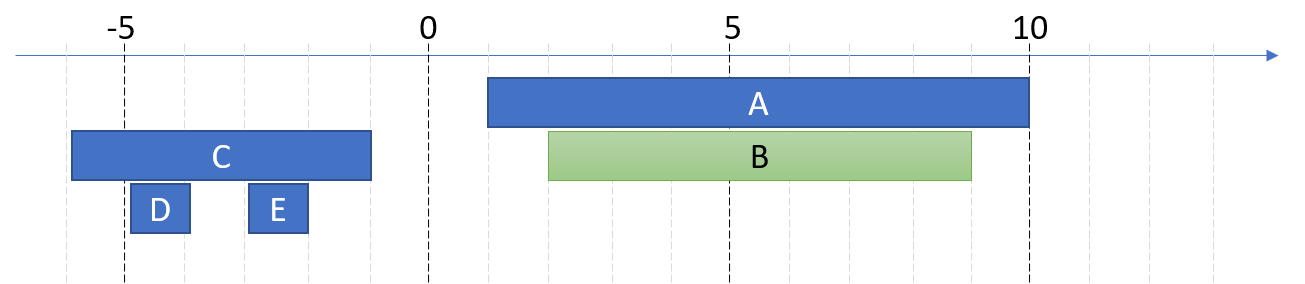
目標 node 騰出空間:
B 原本只有 2 ~ 3 (沒有空間再放其他 nodes 了), 擴張到 B(2,9), 騰出待會可以放下三個 nodes 的空間。如果 B 還有其他兄弟 nodes, 也要一起配合挪出位子..
把暫存區的 nodes 搬回來:
B(2,9) 騰出了 3 ~ 8 的 index, 原本被搬到暫存區的 C, D, E 經過計算,全部 index 位移 +9 就可以搬回來新位置了。
經過這三個步驟大功告成。搬移結束。
為何我會先花一些篇幅,甚至畫圖來說明,就是這些觀念不先搞懂的話,你光是看我寫出來的 SQL script, 我保證你一定看不懂我的意圖是什麼,所以我才先解釋觀念。接下來我就一次把 SQL 寫出來,執行看結果了:
-- c:\users 269872,302911
-- c:\windows\backup 303069 303070
;
-- 搬移的參數:
-- * 被搬移的範圍: 269872 ~ 302911 (c:\users)
-- * 搬移目的範圍: 303069 ~ 303070 (c:\windows\backup)
-- step 1, move src to temp area
;
DIRINFO
,
offset
302912
-- step 2, allocate space
;
DIRINFO
offset
303069
DIRINFO
offset
303069
-- step 3, move all nodes in temp area to allocated space
303070
DIRINFO
,
offset
0
-- check result
*
RIGHT_INDEX
root_node
Step 1: 執行時間: 00:00:00.527 (sec) 執行計畫 (Estimated Subtree Cost): 2.69808
Step 2: 執行時間: 00:00:00.116 (sec) 執行計畫 (Estimated Subtree Cost): 2.44647, 2.44594
Step 3: 執行時間: 00:00:00.023 (sec) 執行計畫 (Estimated Subtree Cost): 0.066514
執行時間: 00:00:00.550 (sec)
想確定執行結果的話,我們可以拿 [需求1] 的查詢來驗證看看 c:\windows\backup 下的目錄是不是都搬過來了:
;
*
RIGHT_INDEX
root
exists
(
*
M
RIGHT_INDEX
RIGHT_INDEX
ID
ID
)
查詢結果:

果然, ID = 134937 的 Users 目錄,整包都被搬過來了,執行成功!
需求 5, 刪除目錄
模擬
rm /s /q c:\windows\backup
最後一個需求,如果我要刪除 c:\windows\backup 下的子目錄跟檔案… 這點一直跟前面的方案沒什麼不同,就是先查詢所有的子目錄跟檔案,然後刪除即可。執行的效能關鍵還是一樣,都在如何找出要刪除的清單。
同樣的,為了方便確認結果,我會保留 c:\windows\backup 目錄本身,刪除所有子目錄,及所有的檔案。整個刪除的程序分為三個步驟:
- 選出所有的子目錄 (包含 root), 刪除關聯的檔案
- 刪除所有的子目錄 (不包含 root)
- 回收清出來的 index 空間
-- step 1
(
303070
)
-- step 2
303070
-- step 3
;
;
;
Step 1: 刪除檔案部分 執行時間: 00:00:05.756 (sec) 執行計畫 (Estimated Subtree Cost): 217.166
Step 2: 刪除目錄部分 執行時間: 00:00:00.887 (sec) 執行計畫 (Estimated Subtree Cost): 0.792744
Step 3: 回收索引空間 執行時間: 00:00:02.515 (sec) 執行計畫 (Estimated Subtree Cost): 0.0432873, 12.0335, 11.8227
刪除之後,我們在來查詢 c:\windows\backup 目錄下有多少子目錄掛著:
-- c:\windows\backup 270029 ~ 303070
*
RIGHT_INDEX
--and C.ID <> @root
exists
(
*
M
RIGHT_INDEX
RIGHT_INDEX
ID
ID
)

小結: 三種方案比較
寫到這邊,如何把階層式的資料塞進表格式的關聯式資料庫,縱使還有其他的做法,但是大體也不離這三大類了。
我針對執行的時間結果作了張比較表:
- 模擬
dir c:\windows的結果,列出c:\windows下的目錄與檔案清單,統計檔案的大小 - 模擬
dir /s /b c:\windows\system32\*.ini, 找出所有位於c:\windows\system32目錄下 (包含子目錄) 所有副檔名為.ini的檔案清單
(追加)模擬dir /s /b c:\windows\*.dll, 找出所有位於c:\windows目錄下 (包含子目錄) 所有副檔名為.dll的檔案清單 - 模擬
mkdir c:\windows\backup - 模擬
move c:\users c:\windows\backup - 模擬
rm /s /q c:\windows\backup(叔叔有練過,好孩子不要學)
還記得我測試數據的規模嗎? 複習一下資料庫來源的規模:
- Total Dir(s): 218817
- Total File(s): 1143165
- Max Dir Level: 18
- Max Files In One Dir: 83947
簡單的說,有 110萬筆資料 (files), 有 22萬種分類, 分類階層最高到 18 層, 單一分類底下最多有 8萬筆資料 (非遞迴)。 在這些資料的前提下,SQL 處理這五種需求,花費的時間如下:
| 需求1 | 需求2 | 需求2+ | 需求3 | 需求4 | 需求5 | |
|---|---|---|---|---|---|---|
| 方案1 | 0.279 | 0.547 | 8.138 | 0.028 | 0.026 | 22.536 |
| 方案2 | 0.157 | 0.407 | 0.067 | 0.117 | 0.758 | 20.305 |
| 方案3 | 153.591 | 0.173 | 0.546 | 3.377 | 0.55 | 9.158 |
表格: 執行時間 (Execute Time, sec)
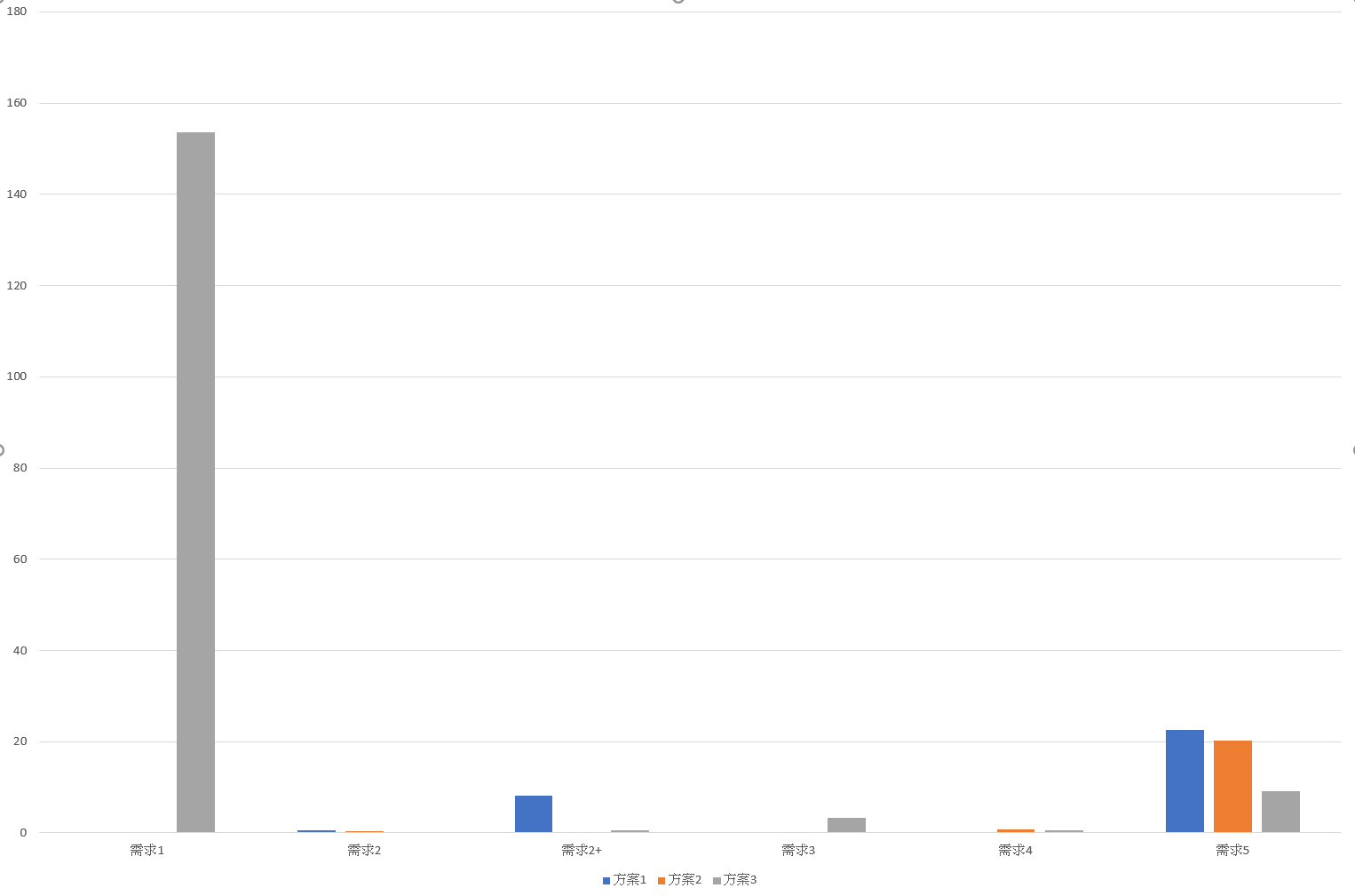
這邊我就針對 web application 最有可能碰到的 case 來探討就好。以我的觀點,我覺得你最應該關心的是這幾項:
- 需求2+, 模擬
dir /s /b c:\windows\*.dll - 需求5, 模擬
rm /s /q c:\windows\backup
為什麼是這兩項? 想像一下,如果你這些資料儲存的是網站上上千萬張照片、商品資料、或是郵件;以及這些資料及分類,你最常對他做什麼操作? 搜尋與大量刪除絕對是首選。至於建立分類會有,但是通常一次建立一個新的,不論哪種方法速度都很快,不大會是設計上的瓶頸。至於搬移,這種機會也不常碰到 (要看你的 application), 通常也是一筆一筆修正居多。
當你需要選擇解決方案時,一定是從你面臨的瓶頸為主,因此我挑選這兩項來總評。
需求 2+, 效能總評
(追加)模擬
dir /s /b c:\windows\*.dll, 找出所有位於c:\windows目錄下 (包含子目錄) 所有副檔名為.dll的檔案清單
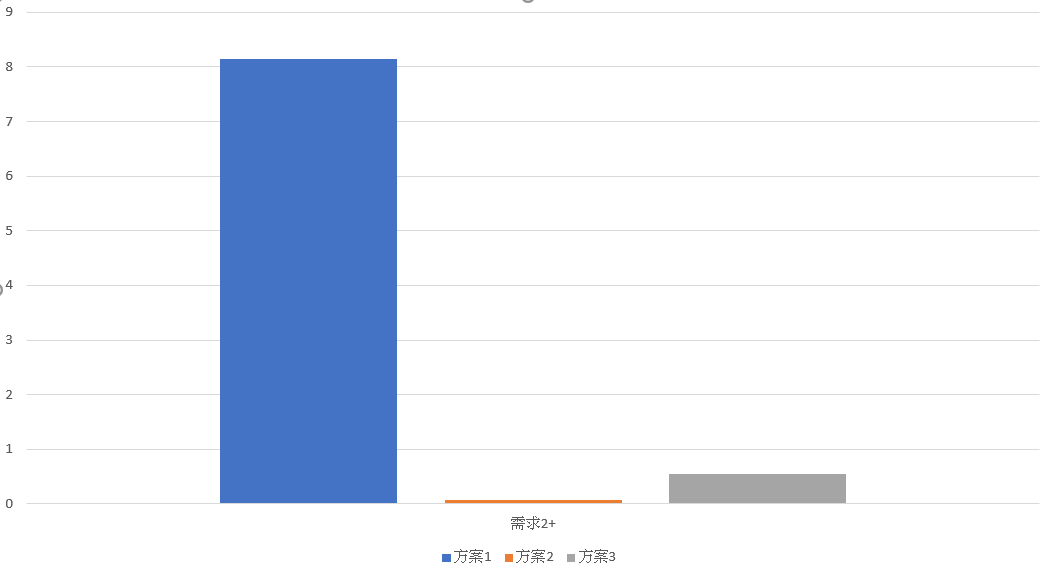
在大型的資料庫內,做遞迴的分類搜尋,你會發現 方案一 使用了遞迴,這正是 RDBMS 最不擅長的計算,硬是執行 Query 的效果非常慘,完全不在同一個檔次身上。至於 方案二 及 方案三,雖說都很快,但是也差了接近 10 倍的時間。我是認為這個差距你可以參考,但是最終應該以整體考量來決定。因為 方案二 獲取效能的代價很高,尤其是在開發與維護方面。
方案二 最大的缺點,就在於 schema 的設計就限制住最大的階層數了。這個範例限制最大階層只能到 20 層;超過的話,TABLE schema 要追加欄位 (這對線上系統而言是大工程),SQL 也要配合改寫 (這也是大工程);SQL 也因為這些欄位,難以寫成靜態好維護的 SQL script, 容易不小心就埋下 SQL Injection 的風險。
也因此,除非你非常需要這 10X 的效能,而且你資料的來源、查詢方式、應用情境你都能嚴格的控制好層數上限,你也不在乎 SQL script 好不好維護的問題時,再考量這個做法。否則我會建議 方案三 是比較均衡可靠的選擇。
需求 5, 效能總評
模擬
rm /s /q c:\windows\backup
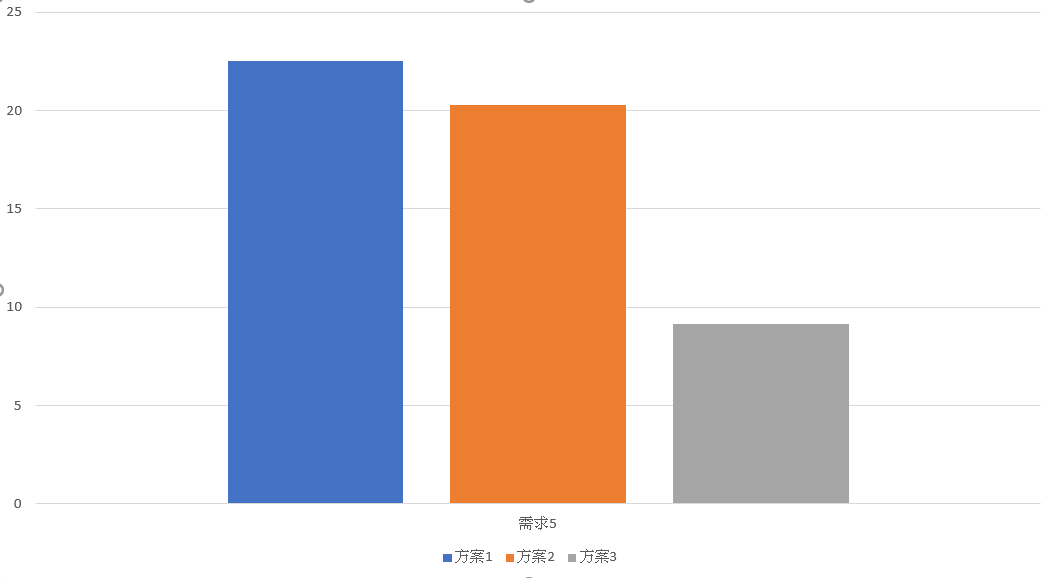
這需求其實就是搜尋 + 刪除的綜合體了。大量刪除的 I/O 時間,沖淡了搜尋速度巨大的差異。三種方式的差異都還在同一個數量及,可以看到 方案三 整體表現最好。其實這個範圍內的差異,我不會太斤斤計較。因為,一來數據本身會有誤差,二來我並沒有很細緻的去調整 INDEX,我相信這個範圍內的差異,很有可能會因為某些環節效能調教而被扭轉的。
不過,即使如此,我仍然會推薦 方案三。因為在前面的搜尋測試,已經剔除 方案一 了, 方案二 又有難以維護的缺點,既然這個需求的評比項目
方案三 的效能也勝出,沒有理由不選他。
總結
在資料庫的世界,用正確的方法 (schema, index, algorithm 等等) 帶來的效益, 遠高於用正確的工具;尤其是你的資料量已經到某個規模之上的時候。這次的範例,我除了 方案一 有用到部分 SQL 特殊語法 (CTE) 之外,其他都是很標準的用法而已。這幾年碰到越來越大規模的系統,越來越大的交易量,加上開始研究 cloud native / microservices 的設計哲學,我開始學到一件事:
如果能預先把資料修飾成最容易使用的模式,資料異動時多花費一些精力把它處理好是值得的。
這種例子很多,這次的案例就都是在建立資料時,預先埋好能解決樹狀資料查詢罩門的額外索引。當然索引是需要額外維護的,你只是把代價從搜尋時期往前挪到更新階段而已。Developer 的任務就是盡量降低缺點,放大優點而已。
其實這三種方案,我是為了讓各位清楚知道區別,才個別使用的;實際上這三種方式是可以混合使用的,只是你開越多種索引,你要維護的工程就越大而以。過去我使用這些技巧時,我甚至做的更徹底,直接把維護索引這些任務,從單純的 SQL script, 往前搬到 application 層次來處理了。前面提到,我過去需要處理大量的 XML data, 因此我寫了一套 XML -> SQL 的轉換引擎。資料異動時,在非表格式的儲存區內 (file, or ntext 欄位) 先異動 XML, 然後再把 XML 拆解成 tree structure 更新到對應的 table… 這時轉換的程序會一併把這些方案必要的 index 也一起計算好,直接寫入 database.
意思是我不需要花太多心思用 SQL 來寫上面搬移 tree 這些指令了。這些操作明顯的用程式語言會來的容易一些。這篇文章其實都沒貼到 C# 的 code, 我就最後來貼一小段吧! 大家知道我這次測試資料怎麼來的嗎? 其實我是寫了一個 .NET 小工具,掃描我的 c:\ 爬了資料出來,逐一寫到 database. 寫的過程中,我一口氣把三種方案需要的索引一次都算出來了,寫到 dbo.DIRINFO, 事後要開始測試時,我才根據 demo1 ~ demo3 的需求,各自把必要的欄位搬出來到各自的 table schema 內驗證。
貼一段我如何產生 data 的 code:
)
{
++;
);
++;
);
>(
PARENT_ID,
FULLNAME,
NAME,
LEVEL_INDEX,
LEFT_INDEX,
PATH1,
PATH2,
(中間省略)
PATH19,
PATH20
) values (
@PARENT_ID,
@FULLNAME,
@NAME,
@LEVEL,
@LEFT,
@PATH1,
@PATH2,
(中間省略)
@PATH19,
@PATH20
); select @@identity;",
new
{
],
,
,
,
,
]),
]),
// 中間省略
]),
]),
});
];
try
{
();
}
catch
{
// no permission
);
}
)
{
>(
DIR_ID,
FULLNAME,
FILE_NAME,
FILE_EXT,
FILE_SIZE
) values (
@DIR_ID,
@FULLNAME,
@FILE_NAME,
@FILE_EXT,
@FILE_SIZE
);
select @@identity;",
{
,
,
,
,
Length
});
++;
;
}
);
;
];
try
{
();
}
catch
{
// no permission
);
}
)
{
// bypass symbol link
++;
;
;
);
;
--;
}
;
++;
(
,
new
{
,
TravelIndex
});
;
}
畢竟 recursive 還是 C# 的強項啊,我用 ProcessFolder( ) 來進行遞迴的處理。過程中直接靠 stack 跟 context 的協助,把 方案二 需要的 20 層索引,還有 方案三 需要的 tree traversal 過程產生的 left / right index 都計算好。
這也給大家一個範例,很多技巧不是原封不動的搬到你的專案就能解決問題的。你必須思考怎麼應用才行,如果你真的像我的案例寫一堆 SQL 去做 tree 的搬移,你們的 DBA 應該會翻白眼吧 XDD。這些技巧不是不能用,而是你應該要判斷,值得用的時候 (或是不得不用時) 再拿出來。
寫在最後: 寫這篇文章的動機
結束之前,來聊一下,我寫這篇文章的動機: 基礎知識的重要性。
走這行的人都知道,東西是學不完的。語言、框架、服務越來越多,你光是通通都要聽過就很困難了,何況還要都 “精通” ? 這根本是不可能的,即使是我也辦不到。因此能在這個行業生存下來的關鍵能力,只有一個: 基礎知識。
我常常都把你能否確實掌握某個技能的能力,分成兩個面相來看,一個是觀念,一個是操作。觀念很難速成的,從不會到會,很多時候要看有沒有好老師或是環境,或是你自己有沒有天分來決定的。但是操作就不是了,操作需要時間去練習與熟悉的,上手的速度通常是線性的,相對較好預估。
觀念就像基礎知識,這個行業的基礎知識其實沒那麼多樣,也相對的長壽。我 20 年前掌握的基礎知識其實到現在都還很好用。操作就不一樣了,隨著工具的汰換,你操作技能大概就沒用了 (例如: 你當年會設定 MS-DOS 的 config.sys, 這技能現在還派的上用場嗎?)。因此我的策略都是盡可能累積基礎知識,而操作技能則是有需要再去學。
自從擔任了架構師的職務之後,更有這種體認了。沒有正確的基礎知識,你的決定可能就會拖垮整個團隊。你永遠需要看清你要解決的問題是什麼,然後根據你的知識來挑選合適的系統與工具,用正確的方式來整合它們,才會發揮最大的效益。這篇文章只是我當年的例子,如果我只是個技術控,我應該會選擇當年相當先進的 Native XML Database 全面導入,最後會搞出一個沒人敢維運的系統 (金融業真的很抗拒這種前衛的方案啊)。有了足夠的基礎知識,我就能清楚如何讓 RDBMS 也能做到一樣的需求。團隊會有更多的精神把需求做好,也有更充裕的空間作好長期轉移到對的系統 (如 NOSQL) 的規劃與準備。
最後,我整理一下這篇題到的幾個參考資料,跟我的範例程式。需要的朋友請自行取用:
- 範例程式: Andrew.NestedQueryDemo
包含把目錄結構匯入 SQLDB 的 .NET Console App, 以及對應的 SQLDB Database Project
with-common-table-expression-transact-sql?view=sql-server-2017) - 黑暗執行緒: SQL 2005 T-SQL Enhancement: Common Table Expression
- 黑暗執行緒: ORACLE筆記-使用 CONNECT BY 呈現階層化資料
- Rico技術農場:
SQL SERVER hirearchy method - Wiki: Nested Set Model
- SQL Server Common Table Expression: CTE
- 網友提供: Modified Preorder Tree Traversal (這篇講方案三講得更清楚)
